系统安全性架构
关键词:XSS、CSRF、SQL 注入、DoS、消息摘要、加密算法、证书
一、认证 SSO SSO(Single Sign On),即单点登录 。所谓单点登录,就是同平台的诸多应用登陆一次,下一次就免登陆的功能。
SSO 需要解决多个异构系统之间的问题:
Session 共享问题 分布式 Session 的几种实现策略:
粘性 Session - 缺点:当服务器节点宕机时,将丢失该服务器节点上的所有 Session 。
应用服务器间的 Session 复制共享 - 缺点:占用过多内存 ;同步过程占用网络带宽以及服务器处理器时间 。
基于缓存的 Session 共享 ✅ (推荐方案) - 不过需要程序自身控制 Session 读写,可以考虑基于 spring-session + redis 这种成熟的方案来处理。
详情请参考:Session 原理
Cookie 跨域 Cookie 不能跨域 !比如:浏览器不会把 www.google.com 的 cookie 传给 www.baidu.com。
这就存在一个问题:由于域名不同,用户在系统 A 登录后,浏览器记录系统 A 的 Cookie,但是访问系统 B 的时候不会携带这个 Cookie。
针对 Cookie 不能跨域 的问题,有几种解决方案:
服务端生成 Cookie 后,返回给客户端,客户端解析 Cookie ,提取 Token (比如 JWT),此后每次请求都携带这个 Token。
多个域名共享 Cookie,在返回 Cookie 给客户端的时候,在 Cookie 中设置 domain 白名单。
将 Token 保存在 SessionStroage
CAS CAS 是实现 SSO 的主流方式。
CAS 分为两部分,CAS Server 和 CAS Client
CAS ServerCAS Client
术语:
Ticket Granting Ticket (TGT)Ticket Granting Cookie (TGC)Service Ticket (ST)
CAS 工作流程:
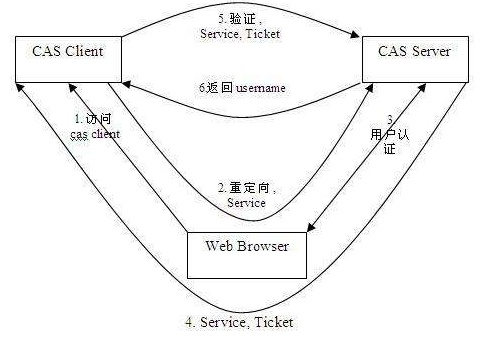
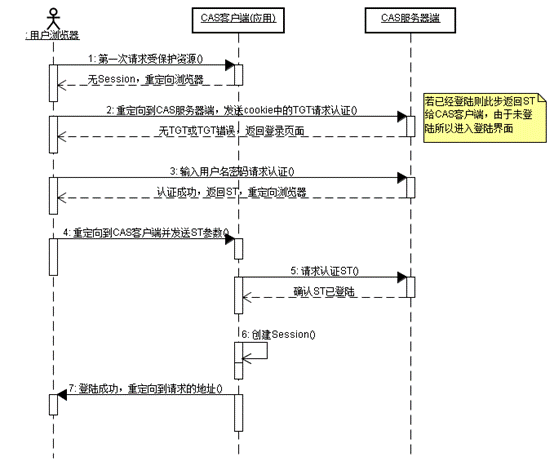
用户访问 CAS Client A(业务系统),第一次访问,重定向到认证服务中心(CAS Server)。CAS Server 发现当前请求中没有 Cookie,再重定向到 CAS Server 的登录页面。重定向请求的 URL 中包含访问地址,以便认证成功后直接跳转到访问页面。
用户在登录页面输入用户名、密码等认证信息,认证成功后,CAS Server 生成 TGT,再用 TGT 生成一个 ST。然后返回 ST 和 TGC(Cookie)给浏览器。
浏览器携带 ST 再度访问之前想访问的 CAS Client A 页面。
CAS Client A 收到 ST 后,向 CAS Server 验证 ST 的有效性。验证通过则允许用户访问页面。
此时,如果登录另一个 CAS Client B,会先重定向到 CAS Server,CAS Server 可以判断这个 CAS Client B 是第一次访问,但是本地有 TGC,所以无需再次登录。用 TGC 创建一个 ST,返回给浏览器。
重复类似 3、4 步骤。
以上了归纳总结如下:
访问服务 - 用户访问 SSO Client 资源。
定向认证 - SSO Client 重定向用户请求到 SSO Server。
用户认证 - 用户身份认证。
发放票据 - SSO Server 会产生一个 Service Ticket (ST) 并返回给浏览器。
验证票据 - 浏览器每次访问 SSO Client 时,携带 ST,SSO Client 向 SSO Server 验证票据。只有验证通过,才允许访问。
传输用户信息 - SSO Server 验证票据通过后,传输用户认证结果信息给 SSO Client。
Oauth 2.0 基本原理 OAuth 在”客户端”与”服务提供商”之间,设置了一个授权层(authorization layer)。”客户端”不能直接登录”服务提供商”,只能登录授权层,以此将用户与客户端区分开来。”客户端”登录授权层所用的令牌(token),与用户的密码不同。用户可以在登录的时候,指定授权层令牌的权限范围和有效期。
“客户端”登录授权层以后,”服务提供商”根据令牌的权限范围和有效期,向”客户端”开放用户储存的资料。
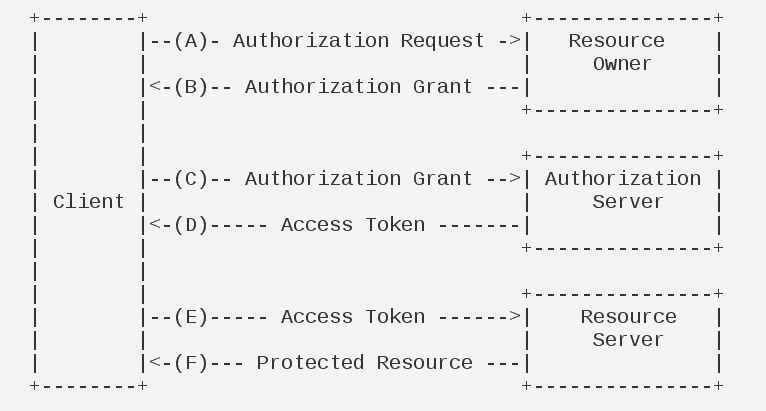
OAuth 2.0 的运行流程如下图,摘自 RFC 6749。
(A)用户打开客户端以后,客户端要求用户给予授权。
(B)用户同意给予客户端授权。
(C)客户端使用上一步获得的授权,向认证服务器申请令牌。
(D)认证服务器对客户端进行认证以后,确认无误,同意发放令牌。
(E)客户端使用令牌,向资源服务器申请获取资源。
(F)资源服务器确认令牌无误,同意向客户端开放资源。
不难看出来,上面六个步骤之中,B 是关键,即用户怎样才能给于客户端授权。有了这个授权以后,客户端就可以获取令牌,进而凭令牌获取资源。
授权模式 客户端必须得到用户的授权(authorization grant),才能获得令牌(access token)。OAuth 2.0 定义了四种授权方式。
授权码模式(authorization code)
简化模式(implicit)
密码模式(resource owner password credentials)
客户端模式(client credentials)
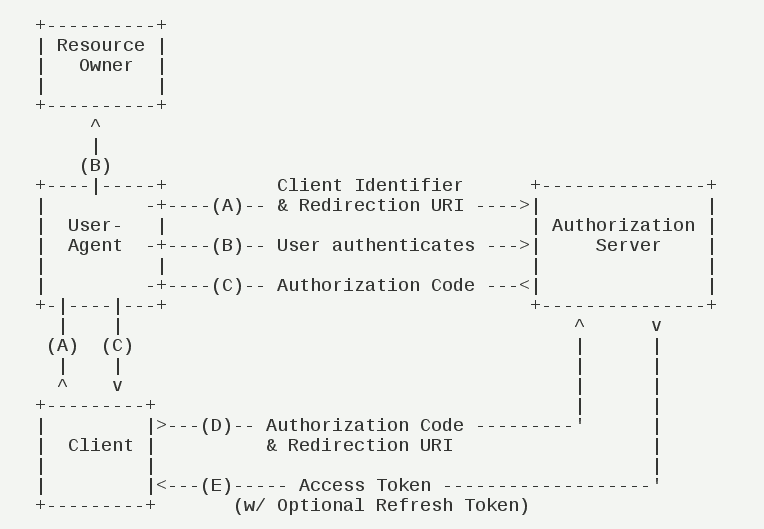
授权码模式 授权码模式(authorization code)是功能最完整、流程最严密的授权模式。它的特点就是通过客户端的后台服务器,与”服务提供商”的认证服务器进行互动。
它的步骤如下:
(A)用户访问客户端,后者将前者导向认证服务器。
(B)用户选择是否给予客户端授权。
(C)假设用户给予授权,认证服务器将用户导向客户端事先指定的”重定向 URI”(redirection URI),同时附上一个授权码。
(D)客户端收到授权码,附上早先的”重定向 URI”,向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。
(E)认证服务器核对了授权码和重定向 URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。
下面是上面这些步骤所需要的参数。
A 步骤中,客户端申请认证的 URI,包含以下参数:
response_type:表示授权类型,必选项,此处的值固定为”code”
client_id:表示客户端的 ID,必选项
redirect_uri:表示重定向 URI,可选项
scope:表示申请的权限范围,可选项
state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。
下面是一个例子。
1 2 3 GET /authorize?response_type=code&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host : server.example.com
C 步骤中,服务器回应客户端的 URI,包含以下参数:
code:表示授权码,必选项。该码的有效期应该很短,通常设为 10 分钟,客户端只能使用该码一次,否则会被授权服务器拒绝。该码与客户端 ID 和重定向 URI,是一一对应关系。
state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。
下面是一个例子。
1 2 3 HTTP/1.1 302 FoundLocation : https://client.example.com/cb?code=SplxlOBeZQQYbYS6WxSbIA &state=xyz
D 步骤中,客户端向认证服务器申请令牌的 HTTP 请求,包含以下参数:
grant_type:表示使用的授权模式,必选项,此处的值固定为”authorization_code”。
code:表示上一步获得的授权码,必选项。
redirect_uri:表示重定向 URI,必选项,且必须与 A 步骤中的该参数值保持一致。
client_id:表示客户端 ID,必选项。
下面是一个例子。
1 2 3 4 5 6 7 POST /token HTTP/1.1 Host : server.example.comAuthorization : Basic czZCaGRSa3F0MzpnWDFmQmF0M2JWContent-Type : application/x-www-form-urlencodedgrant_type= authorization_code&code= SplxlOBeZQQYbYS6 WxSbIA &redirect_uri= https%3 A%2 F%2 Fclient%2 Eexample%2 Ecom%2 Fcb
E 步骤中,认证服务器发送的 HTTP 回复,包含以下参数:
access_token:表示访问令牌,必选项。
token_type:表示令牌类型,该值大小写不敏感,必选项,可以是 bearer 类型或 mac 类型。
expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。
refresh_token:表示更新令牌,用来获取下一次的访问令牌,可选项。
scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。
下面是一个例子。
1 2 3 4 5 6 7 8 9 10 11 12 HTTP/1.1 200 OKContent-Type : application/json;charset=UTF-8Cache-Control : no-storePragma : no-cache{ "access_token" : "2YotnFZFEjr1zCsicMWpAA" , "token_type" : "example" , "expires_in" : 3600 , "refresh_token" : "tGzv3JOkF0XG5Qx2TlKWIA" , "example_parameter" : "example_value" }
从上面代码可以看到,相关参数使用 JSON 格式发送(Content-Type: application/json)。此外,HTTP 头信息中明确指定不得缓存。
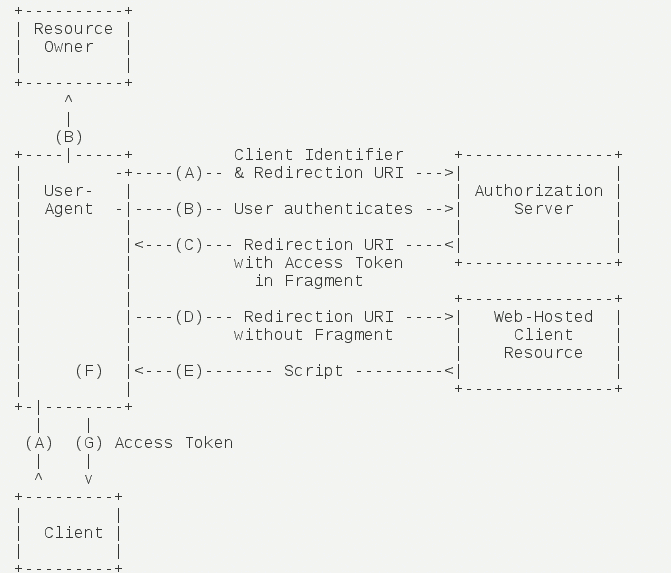
简化模式 简化模式(implicit grant type)不通过第三方应用程序的服务器,直接在浏览器中向认证服务器申请令牌,跳过了”授权码”这个步骤,因此得名。所有步骤在浏览器中完成,令牌对访问者是可见的,且客户端不需要认证。
它的步骤如下:
(A)客户端将用户导向认证服务器。
(B)用户决定是否给于客户端授权。
(C)假设用户给予授权,认证服务器将用户导向客户端指定的”重定向 URI”,并在 URI 的 Hash 部分包含了访问令牌。
(D)浏览器向资源服务器发出请求,其中不包括上一步收到的 Hash 值。
(E)资源服务器返回一个网页,其中包含的代码可以获取 Hash 值中的令牌。
(F)浏览器执行上一步获得的脚本,提取出令牌。
(G)浏览器将令牌发给客户端。
下面是上面这些步骤所需要的参数。
A 步骤中,客户端发出的 HTTP 请求,包含以下参数:
response_type:表示授权类型,此处的值固定为”token”,必选项。
client_id:表示客户端的 ID,必选项。
redirect_uri:表示重定向的 URI,可选项。
scope:表示权限范围,可选项。
state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。
下面是一个例子。
1 2 3 GET /authorize?response_type=token&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host : server.example.com
C 步骤中,认证服务器回应客户端的 URI,包含以下参数:
access_token:表示访问令牌,必选项。
token_type:表示令牌类型,该值大小写不敏感,必选项。
expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。
scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。
state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。
下面是一个例子。
1 2 3 HTTP/1.1 302 FoundLocation : http://example.com/cb#access_token=2YotnFZFEjr1zCsicMWpAA &state=xyz&token_type=example&expires_in=3600
在上面的例子中,认证服务器用 HTTP 头信息的 Location 栏,指定浏览器重定向的网址。注意,在这个网址的 Hash 部分包含了令牌。
根据上面的 D 步骤,下一步浏览器会访问 Location 指定的网址,但是 Hash 部分不会发送。接下来的 E 步骤,服务提供商的资源服务器发送过来的代码,会提取出 Hash 中的令牌。
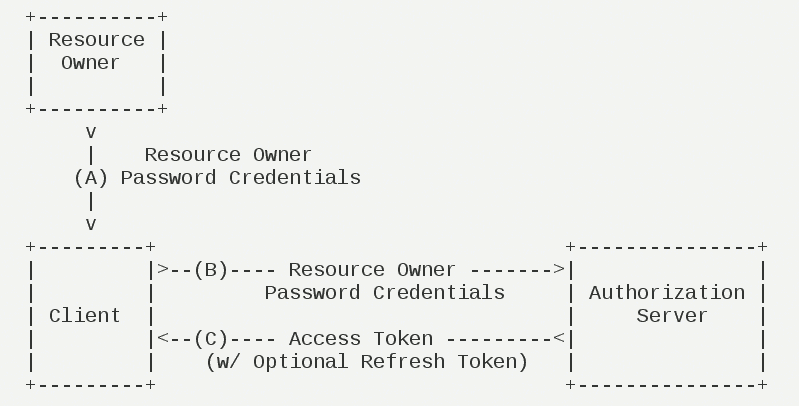
密码模式
密码模式(Resource Owner Password Credentials Grant)中,用户向客户端提供自己的用户名和密码。客户端使用这些信息,向”服务商提供商”索要授权。
在这种模式中,用户必须把自己的密码给客户端,但是客户端不得储存密码。这通常用在用户对客户端高度信任的情况下,比如客户端是操作系统的一部分,或者由一个著名公司出品。而认证服务器只有在其他授权模式无法执行的情况下,才能考虑使用这种模式。
它的步骤如下:
(A)用户向客户端提供用户名和密码。
(B)客户端将用户名和密码发给认证服务器,向后者请求令牌。
(C)认证服务器确认无误后,向客户端提供访问令牌。
B 步骤中,客户端发出的 HTTP 请求,包含以下参数:
grant_type:表示授权类型,此处的值固定为”password”,必选项。
username:表示用户名,必选项。
password:表示用户的密码,必选项。
scope:表示权限范围,可选项。
下面是一个例子。
1 2 3 4 5 6 POST /token HTTP/1.1 Host : server.example.comAuthorization : Basic czZCaGRSa3F0MzpnWDFmQmF0M2JWContent-Type : application/x-www-form-urlencodedgrant_type = password&username =johndoe&password =A3ddj3w
C 步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。
1 2 3 4 5 6 7 8 9 10 11 12 HTTP/1.1 200 OKContent-Type : application/json;charset=UTF-8Cache-Control : no-storePragma : no-cache{ "access_token" : "2YotnFZFEjr1zCsicMWpAA" , "token_type" : "example" , "expires_in" : 3600 , "refresh_token" : "tGzv3JOkF0XG5Qx2TlKWIA" , "example_parameter" : "example_value" }
上面代码中,各个参数的含义参见《授权码模式》一节。
整个过程中,客户端不得保存用户的密码。
客户端模式
客户端模式(Client Credentials Grant)指客户端以自己的名义,而不是以用户的名义,向”服务提供商”进行认证。严格地说,客户端模式并不属于 OAuth 框架所要解决的问题。在这种模式中,用户直接向客户端注册,客户端以自己的名义要求”服务提供商”提供服务,其实不存在授权问题。
它的步骤如下:
(A)客户端向认证服务器进行身份认证,并要求一个访问令牌。
(B)认证服务器确认无误后,向客户端提供访问令牌。
A 步骤中,客户端发出的 HTTP 请求,包含以下参数:
granttype:表示授权类型,此处的值固定为”client credentials”,必选项。
scope:表示权限范围,可选项。
1 2 3 4 5 6 POST /token HTTP/1.1 Host : server.example.comAuthorization : Basic czZCaGRSa3F0MzpnWDFmQmF0M2JWContent-Type : application/x-www-form-urlencodedgrant_type =client_credentials
认证服务器必须以某种方式,验证客户端身份。
B 步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。
1 2 3 4 5 6 7 8 9 10 11 HTTP/1.1 200 OKContent-Type : application/json;charset=UTF-8Cache-Control : no-storePragma : no-cache{ "access_token" : "2YotnFZFEjr1zCsicMWpAA" , "token_type" : "example" , "expires_in" : 3600 , "example_parameter" : "example_value" }
上面代码中,各个参数的含义参见《授权码模式》一节。
更新令牌 如果用户访问的时候,客户端的”访问令牌”已经过期,则需要使用”更新令牌”申请一个新的访问令牌。
客户端发出更新令牌的 HTTP 请求,包含以下参数:
granttype:表示使用的授权模式,此处的值固定为”refresh token”,必选项。
refresh_token:表示早前收到的更新令牌,必选项。
scope:表示申请的授权范围,不可以超出上一次申请的范围,如果省略该参数,则表示与上一次一致。
下面是一个例子。
1 2 3 4 5 6 POST /token HTTP/1.1 Host : server.example.comAuthorization : Basic czZCaGRSa3F0MzpnWDFmQmF0M2JWContent-Type : application/x-www-form-urlencodedgrant_type=ref resh_token&ref resh_token=tGzv3JOkF0XG5Qx2TlKWIA
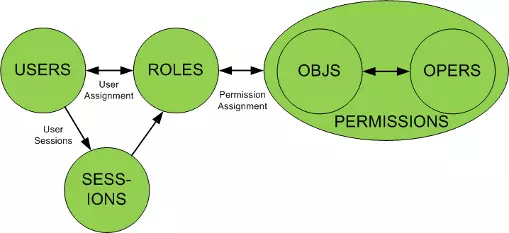
二、鉴权 RBAC 基于角色的访问控制(RBAC: Role-Based Access Control)
每个用户关联一个或多个角色,每个角色关联一个或多个权限,从而可以实现了非常灵活的权限管理。角色可以根据实际业务需求灵活创建,这样就省去了每新增一个用户就要关联一遍所有权限的麻烦。简单来说 RBAC 就是:用户关联角色,角色关联权限。
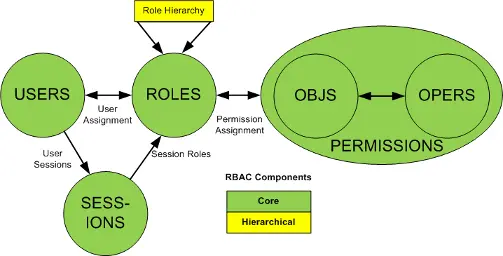
角色继承 角色继承(Hierarchical Role) 就是指角色可以继承于其他角色,在拥有其他角色权限的同时,自己还可以关联额外的权限。这种设计可以给角色分组和分层,一定程度简化了权限管理工作。
职责分离(Separation of Duty) 为了避免用户拥有过多权限而产生利益冲突,例如一个篮球运动员同时拥有裁判的权限(看一眼就给你判犯规狠不狠?),另一种职责分离扩展版的 RBAC 被提出。
职责分离有两种模式:
静态职责分离(Static Separation of Duty):用户无法同时被赋予有冲突的角色。
动态职责分离(Dynamic Separation of Duty):用户在一次会话(Session)中不能同时激活自身所拥有的、互相有冲突的角色,只能选择其一。
讲了这么多 RBAC,都还只是在用户和权限之间进行设计,并没有涉及到用户和对象之间的权限判断,而在实际业务系统中限制用户能够使用的对象是很常见的需求。
三、审计 TODO
四、网站攻击 互联网环境鱼龙混杂,网站被攻击是常见现象,所以了解一些常见的网站攻击手段十分必要。下面列举比较常见的 4 种攻击手段:
XSS 概念 跨站脚本(Cross-site scripting,通常简称为XSS)
XSS 攻击示例:
假如有下面一个 textbox
1 <input type ="text" name ="address1" value ="value1from" />
value1from 是来自用户的输入,如果用户不是输入 value1from,而是输入 "/><script>alert(document.cookie)</script><!- 那么就会变成:
1 2 3 4 5 <input type ="text" name ="address1" value ="" /> <script > alert (document .cookie ) </script > <!- ">
嵌入的 JavaScript 代码将会被执行。攻击的威力,取决于用户输入了什么样的脚本。
攻击手段和目的 常用的 XSS 攻击手段和目的有:
盗用 cookie,获取敏感信息。
利用植入 Flash,通过 crossdomain 权限设置进一步获取更高权限;或者利用 Java 等得到类似的操作。
利用 iframe、frame、XMLHttpRequest 或上述 Flash 等方式,以(被攻击)用户的身份执行一些管理动作,或执行一些一般的如发微博、加好友、发私信等操作。
利用可被攻击的域受到其他域信任的特点,以受信任来源的身份请求一些平时不允许的操作,如进行不当的投票活动。
在访问量极大的一些页面上的 XSS 可以攻击一些小型网站,实现 DDoS 攻击的效果。
应对手段
过滤特殊字符 - 将用户所提供的内容进行过滤,从而避免 HTML 和 Jascript 代码的运行。如 > 转义为 >、< 转义为 < 等,就可以防止大部分攻击。为了避免对不必要的内容错误转移,如 3<5 中的 < 需要进行文本匹配后再转移,如:<img src= 这样的上下文中的 < 才转义。设置 Cookie 为 HttpOnly - 设置了 HttpOnly 的 Cookie 可以防止 JavaScript 脚本调用,就无法通过 document.cookie 获取用户 Cookie 信息。
:point_right: 参考阅读:
CSRF 概念 **跨站请求伪造(Cross-site request forgery,CSRF)**,也被称为 one-click attack 或者 session riding,通常缩写为 CSRF 或者 XSRF。它是一种挟持用户在当前已登录的 Web 应用程序上执行非本意的操作的攻击方法。和跨站脚本(XSS)相比,XSS 利用的是用户对指定网站的信任,CSRF 利用的是网站对用户网页浏览器的信任。
攻击手段和目的 可以如此理解 CSRF:攻击者盗用了你的身份,以你的名义发送恶意请求。
CSRF 能做的事太多:
以你名义发送邮件,发消息
用你的账号购买商品
用你的名义完成虚拟货币转账
泄露个人隐私
…
应对手段
表单 Token - CSRF 是一个伪造用户请求的操作,所以需要构造用户请求的所有参数才可以。表单 Token 通过在请求参数中添加随机数的办法来阻止攻击者获得所有请求参数。验证码 - 请求提交时,需要用户输入验证码,以避免用户在不知情的情况下被攻击者伪造请求。Referer check - HTTP 请求头的 Referer 域中记录着请求资源,可通过检查请求来源,验证其是否合法。
:point_right: 参考阅读:
SQL 注入 概念 **SQL 注入攻击(SQL injection)**,是发生于应用程序之数据层的安全漏洞。简而言之,是在输入的字符串之中注入 SQL 指令,在设计不良的程序当中忽略了检查,那么这些注入进去的指令就会被数据库服务器误认为是正常的 SQL 指令而运行,因此遭到破坏或是入侵。
攻击示例:
考虑以下简单的登录表单:
1 2 3 4 5 <form action ="/login" method ="POST" > <p > Username: <input type ="text" name ="username" /> </p > <p > Password: <input type ="password" name ="password" /> </p > <p > <input type ="submit" value ="登陆" /> </p > </form >
我们的处理里面的 SQL 可能是这样的:
1 2 3 username:= r.Form.Get("username") password:= r.Form.Get("password") sql := "SELECT * FROM user WHERE username='"+ username+ "' AND password='"+ password+ "'"
如果用户的输入的用户名如下,密码任意
1 myuser' or ' foo' = ' foo' --
那么我们的 SQL 变成了如下所示:
1 SELECT * FROM user WHERE username= 'myuser' or 'foo' = 'foo'
在 SQL 里面 -- 是注释标记,所以查询语句会在此中断。这就让攻击者在不知道任何合法用户名和密码的情况下成功登录了。
对于 MSSQL 还有更加危险的一种 SQL 注入,就是控制系统,下面这个可怕的例子将演示如何在某些版本的 MSSQL 数据库上执行系统命令。
1 2 sql := "SELECT * FROM products WHERE name LIKE '%"+ prod+ "%'"Db.Exec(sql )
如果攻击提交 a%' exec master..xp_cmdshell 'net user test testpass /ADD' -- 作为变量 prod 的值,那么 sql 将会变成
1 sql := "SELECT * FROM products WHERE name LIKE '%a%' exec master..xp_cmdshell 'net user test testpass /ADD'--%'"
MSSQL 服务器会执行这条 SQL 语句,包括它后面那个用于向系统添加新用户的命令。如果这个程序是以 sa 运行而 MSSQLSERVER 服务又有足够的权限的话,攻击者就可以获得一个系统帐号来访问主机了。
虽然以上的例子是针对某一特定的数据库系统的,但是这并不代表不能对其它数据库系统实施类似的攻击。针对这种安全漏洞,只要使用不同方法,各种数据库都有可能遭殃。
攻击手段和目的
数据表中的数据外泄,例如个人机密数据,账户数据,密码等。
数据结构被黑客探知,得以做进一步攻击(例如 SELECT * FROM sys.tables)。
数据库服务器被攻击,系统管理员账户被窜改(例如 ALTER LOGIN sa WITH PASSWORD='xxxxxx')。
获取系统较高权限后,有可能得以在网页加入恶意链接、恶意代码以及 XSS 等。
经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统(例如 xp_cmdshell “net stop iisadmin”可停止服务器的 IIS 服务)。
破坏硬盘数据,瘫痪全系统(例如 xp_cmdshell “FORMAT C:”)。
应对手段
使用参数化查询 - 建议使用数据库提供的参数化查询接口,参数化的语句使用参数而不是将用户输入变量嵌入到 SQL 语句中,即不要直接拼接 SQL 语句。例如使用 database/sql 里面的查询函数 Prepare 和 Query ,或者 Exec(query string, args ...interface{})。单引号转换 - 在组合 SQL 字符串时,先针对所传入的参数进行字符替换(将单引号字符替换为连续 2 个单引号字符)。
:point_right: 参考阅读:
DoS **拒绝服务攻击(denial-of-service attack, DoS)亦称洪水攻击**,是一种网络攻击手法,其目的在于使目标电脑的网络或系统资源耗尽,使服务暂时中断或停止,导致其正常用户无法访问。
当黑客使用网络上两个或以上被攻陷的电脑作为“僵尸”向特定的目标发动“拒绝服务”式攻击时,称为分布式拒绝服务攻击(distributed denial-of-service attack,缩写:DDoS attack、DDoS)。
攻击方式
应对手段
防火墙 - 允许或拒绝特定通讯协议,端口或 IP 地址。当攻击从少数不正常的 IP 地址发出时,可以简单的使用拒绝规则阻止一切从攻击源 IP 发出的通信。路由器、交换机 - 具有速度限制和访问控制能力。流量清洗 - 通过采用抗 DDoS 软件处理,将正常流量和恶意流量区分开。
:point_right: 参考阅读:
五、加密技术 对于网站来说,用户信息、账户等等敏感数据一旦泄漏,后果严重,所以为了保护数据,应对这些信息进行加密处理。
信息加密技术一般分为:
消息摘要 常用数字签名算法:MD5、SHA 等。
应用场景:将用户密码以消息摘要形式保存到数据库中。
:point_right: 参考阅读:
加密算法 对称加密 对称加密指加密和解密所使用的密钥是同一个密钥。
常用对称加密算法:DES、AES 等。
应用场景:Cookie 加密、通信机密等。
非对称加密 非对称加密指加密和解密所使用的不是同一个密钥,而是一个公私钥对。用公钥加密的信息必须用私钥才能解开;反之,用私钥加密的信息只有用公钥才能解开。
常用非对称加密算法:RSA 等。
应用场景:HTTPS 传输中浏览器使用的数字证书实质上是经过权威机构认证的非对称加密公钥。
:point_right: 参考阅读:
密钥安全管理 保证密钥安全的方法:
把密钥和算法放在一个独立的服务器上,对外提供加密和解密服务,应用系统通过调用这个服务,实现数据的加解密。
把加解密算法放在应用系统中,密钥则放在独立服务器中,为了提高密钥的安全性,实际存储时,密钥被切分成数片,加密后分别保存在不同存储介质中。
证书 证书可以称为信息安全加密的终极手段 。公开密钥认证(英语:Public key certificate),又称公开密钥证书、公钥证书、数字证书(digital certificate)、数字认证、身份证书(identity certificate)、电子证书或安全证书,是用于公开密钥基础建设的电子文件,用来证明公开密钥拥有者的身份。此文件包含了公钥信息、拥有者身份信息(主体)、以及数字证书认证机构(发行者)对这份文件的数字签名,以保证这个文件的整体内容正确无误。
透过信任权威数字证书认证机构的根证书、及其使用公开密钥加密作数字签名核发的公开密钥认证,形成信任链架构,已在 TLS 实现并在万维网的 HTTP 以 HTTPS、在电子邮件的 SMTP 以 STARTTLS 引入并广泛应用。
众所周知,常见的应用层协议 HTTP、FTP、Telnet 本身不保证信息安全。但是加入了 SSL/TLS 加密数据包机制的 HTTPS、FTPS、Telnets 是信息安全的。传输层安全性协议(Transport Layer Security, TLS),及其前身安全套接层(Secure Sockets Layer, SSL)是一种安全协议,目的是为互联网通信,提供安全及数据完整性保障。
证书原理 SSL/TLS 协议的基本思路是采用公钥加密法,也就是说,客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
这里有两个问题:
(1)如何保证公钥不被篡改?
解决方法:将公钥放在数字证书中。只要证书是可信的,公钥就是可信的。
(2)公钥加密计算量太大,如何减少耗用的时间?
解决方法:每一次对话(session),客户端和服务器端都生成一个”对话密钥”(session key),用它来加密信息。由于”对话密钥”是对称加密,所以运算速度非常快,而服务器公钥只用于加密”对话密钥”本身,这样就减少了加密运算的消耗时间。
SSL/TLS 协议的基本过程是这样的:
客户端向服务器端索要并验证公钥。
双方协商生成”对话密钥”。
双方采用”对话密钥”进行加密通信。
:point_right: 参考阅读:
六、信息过滤 在网络中,广告和垃圾信息屡见不鲜,泛滥成灾。
常见的信息过滤与反垃圾手段有:
文本匹配 解决敏感词过滤。系统维护一份敏感词清单,如果信息中含有敏感词,则自动进行过滤或拒绝信息。
黑名单 黑名单就是将一些已经被识别出有违规行为的 IP、域名、邮箱等加入黑名单,拒绝其请求。
黑名单可以通过 Hash 表来实现,方法简单,复杂度小,适于一般应用场景。
但如果黑名单列表非常大时,Hash 表要占用很大的内存空间,这时就不再使用了。这种情况下,可以使用布隆过滤器来实现,即通过一个二进制列表和一组随机数映射函数来实现。
分类算法 对于海量信息,难以通过人工去审核。对广告贴。
垃圾邮件等内容的识别比较好的自动化方法就是采用分类算法。
简单来说,即将批量已分类的样本输入分类算法进行训练,得到一个分类模型,然后利用分类算法结合分类模型去对信息进行识别。想了解具体做法,需要去理解机器学习相关知识。
七、风险控制 网络给商务、金融领域带来极大便利的同时,也将风险带给了对网络安全一无所知的人们。由于交易双方信息的不对等,使得交易存在着风险,而当交易发生在网络上时,风险就更加难以控制了。
风险种类
账户风险 - 盗用账户、恶意注册账户等
买家风险 - 虚假询盘、恶意拒收、恶意下单、黄牛党抢购热门商品等
卖家风险 - 虚假发货、出售违禁品、侵权等
交易风险 - 信用卡盗刷、交易欺诈、洗钱、套现、电信诈骗等
风险控制手段 大型电商网站系统或金融系统都配备专业的风控团队进行风险控制。风险控制手段既包括人工审核也包括自动审核。
自动风控的技术手段主要有规则引擎和统计模型。
规则引擎 在交易中,买家、卖家的某些指标满足一定条件时,就会被认为存在风险。如:交易金额超过某个数值;用户来自黑名单;用户和上次登录的地址距离差距很大;用户在一定时间内频繁交易等等。
如果以上这些条件都通过 if … else … 式样的代码去实现,代码维护、扩展会非常不便。因此,就有了规则引擎来处理这类问题。规则引擎是一种将业务规则和规则处理逻辑相分离的技术,业务规则由运营人员通过管理界面去编辑,实现无需修改代码,即可实时的使用新规则。
统计模型 规则引擎虽然技术简单,但是随着规则不断增加,规模越来越大。可能会出现规则冲突,难以维护的情况,并且规则越多,性能也越差。
为了解决这种问题,就有了统计模型。统计模型会使用分类算法或更复杂的机器学习算法进行智能统计。根据历史交易中的信息训练分类,然后将经过采集加工后的交易信息输入分类算法,得到交易风险值,然后基于此,做出预测。
经过充分训练后的统计模型,准确率不低于规则引擎。但是,需要有领域专家、行业专家介入,建立合理的训练模型,并不断优化。
参考资料