Golang 中栈、队列的实现及常用操作,数据结构系列原文:flaviocopes.com,翻译已获作者授权。
Golang 数据结构:链表
Golang 中链表的实现及常用操作,数据结构系列原文:flaviocopes.com,翻译已获作者授权。
解决连通性问题的四种算法
最近做 B 站弹幕分析
连通性问题
问题概述
先来看一张图:

在这个彼此连接和断开的点网络中,我们可以找到一条 p 点到 q 点的路径。在计算机网络中判断两台主机是否连通、在社交网络中判断两个用户是否存在间接社交关系等,都可以抽象成连通性问题。
问题抽象
可将网络中的点(主机、人)抽象为对象,p-q 表示 p连接到q,连通关系可传递: p-q & q-r => p-r;为简述问题,将两个对象标记为一个整数对,则给定整数对序列就能描述出点网络。
如下图结点数 N = 5 的网络(使用 0 ~ N-1表示对象),可用整数对序列 0-1 1-3 2-4 来描述连通关系, 其中 0 和 3 也是连通的,存在两个连通分量:{0, 1, 3} 和 {2, 4}

问题:给定描述连通关系的整数对序列,任给其中两个整数 p 和 q,判断其是否能连通?
问题示例
1 | 输入 不连通 连通 |
对应的连通图如下,黑线表示首次连接两个结点,绿线表示两结点已存在连通关系: 
算法一:快速查找算法
使用数组 id[i] 存储结点的值, i 为结点序号,即初始状态序号和数组值相同 : 
当输入前两个连通关系后, id[i] 变化如下: 
可以看出, id[i] 的值是完成连通后,i 连接到的终点结点。若 p 和 q 连通,则 id[p] 和 id[q] 值应相等。
如完成 4-9 后, id[3] 和 id[4] 的值均为终点结点 9。此时判断 3 和 9 是否连通,直接判断 id[3] 和 id[9] 的值是否相等,相等则连通,不等则不存在连通关系。显然 id[3] == id[9] == 9,即存在连通关系。
算法实现
1 | /** file: 1.1-quick_find.go */ |
运行效果:能判断 2-9 已存在连通关系

复杂度
快速查找算法在判断 p 和 q 是否连通时,只需判断 id[p] 和 id[q] 是否相等。但 p 和 q 不连通时会进行合并,每次合并都需要遍历整个数组。特性:查找快、合并慢
算法二:快速合并算法
概述
快速查找算法每次合并都会全遍历数组导致低效。我们想能不能不要每次都遍历 id[] ,优化为每次只遍历数组的部分值,复杂度都会降低。
这时应想到树结构,在连通关系的传递性中,p->r & q->r => p->q,可将 r 视为根,p 和 q 视为子结点,因为 p 和 q 有相同的根 r,所以 p 和 q 是连通的。这里的树是连通关系的抽象。
数据结构
使用数组作为树的实现:
- 结点数组
id[N],id[i]存放i的父结点 i的根结点是id[id[...id[i]...]],不断向上找父结点的父结点…直到根结点(父结点是自身)
使用树的优势
将整数对序列的表示从数组改为树,每个结点存储它的父结点位置,这种树有 2 点好处:
- 判断 p 和 q 是否连通:是否有相同的根结点
- 合并 p 到 q:将 p 的根结点改为 q 的根结点(无需全遍历,快速合并)
例子:
对于上边的整数对序列,查找、合并过程如下,橙色是合并动作、灰色是已连通状态、绿色是存储树的数组。
注意红色的 2-3,不是直接把 2 作为 3 的子结点,而是找到 3 的根结点 9,合并 2-3 与 3-4-9 ,生成 2-9

算法实现:
1 | /** file: 1.2-quick_union.go */ |
算法三:带权快速合并算法
概述
快速合并算法有一个缺陷:数据量很大时,任意合并子树,会导致树越来越高,在查找根结点时要遍历数组大部分的值,依旧会很慢。下图中判断 p、q 是否连通,就需要查找 13 个结点:

如果树合并后的依旧比较矮,各子树之间平衡,则查找根结点会少遍历很多结点,下图中再判断 p、q 是否连通,只需查找 7 个结点:

平衡树的构建
构建平衡的树需要在合并时,将小树合并到大树上,保证合并后的树增高缓慢或者就不增高,从而使大部分的合并需要遍历的结点大大减少。区分小树、大树使用的是树的权值:子树含有结点的个数。
数据结构
树结点的存储依旧使用 id[i] ,但需要一个额外的数组 size[i],记录结点 i 的子结点数。
算法实现
1 | /** |
算法四:路径压缩的加权快速合并算法
概述
加权快速合并算法在大部分整数对都是直接连接的情况下,生成的树依旧会比较高,比如序列:
1 | 10-8 8-6 11-9 12-9 9-6 6-3 7-3 3-1 4-1 5-1 1-0 2-0 |
生成的树如下:

此时判断 9-2 的连通关系,需要分别找到 9 和 2 的根结点。在寻找 9 的根结点时经过 6、3、1树,因为6、3、1树的子节点和 9 一样,根结点都是 0,所以直接把6、3、1树变成 0 的子树。如下: 
优化
每次计算某个节点的根结点时,将沿路检查的结点也指向根结点。尽可能的展平树,在检查连通状态时将大大减少遍历的结点数目。
算法实现
1 | /** |
复杂度
N 是结点集合的大小,T 是树的高度。
| 算法 | 初始化的复杂度 | 合并复杂度 | 查找复杂度 |
|---|---|---|---|
| 快速查找 | N | N(全遍历) | 1(数组取值对比) |
| 快速合并 | N | T(遍历树) | T(遍历树) |
| 带权快速合并 | N | lg N | lg N |
| 路径压缩的带权快速合并 | N | 接近1(树的高度几乎为2) | 接近1 |
总结
上边介绍了 4 种解决连通性问题的算法,从低效完成基本功能的快速查找,到不断优化降低复杂度接近1 的路径压缩带权快速合并。可以学到算法解决程序问题的大致步骤:先完成基本功能,再针对低效操作来优化降低复杂度。
如何学习一门编程语言
📦 本文已归档到:「blog」
前言
很多人喜欢争论什么什么编程语言好,我认为这个话题如果不限定应用范围,就毫无意义。
每种编程语言必然有其优点和缺点,这也决定了它有适合的应用场景和不适合的应用场景。现代软件行业,想一门编程语言包打天下是不现实的。这中现状也造成了一种现象,一个程序员往往要掌握多种编程语言。
学习任何一门编程语言,都会面临的第一个问题都是:如何学习 XX 语言?
我不想说什么多看、多学、多写、多练之类的废话。世上事有难易乎?无他,唯手熟尔。谁不知道熟能生巧的道理?
我觉得有必要谈谈的是:如何由浅入深的学习一门编程语言?学习所有编程语言有没有一个相对统一的学习方法?
曾几何时,当我还是一名小菜鸟时,总是叹服那些大神掌握多门编程语言。后来,在多年编程工作和学习中,我陆陆续续也接触过不少编程语言:C、C++、Java、C#、Javascript、shell 等等。每次学习一门新的编程语言,掌握程度或深或浅,但是学习的曲线却大抵相似。
下面,我按照个人的学习经验总结一下,学习编程语言的基本步骤。
学习编程语言的步骤

基本语法
首先当然是了解语言的最基本语法。
控制台输出,如 C 的 printf,Java 的 System.out.println 等。
普通程序员的第一行代码一般都是输出 “Hello World” 吧。
基本数据类型
不同编程语言的基本数据类型不同。基本数据类型是的申请内存空间变得方便、规范化。
变量
不同编程语言的声明变量方式有很大不同。有的如 Java 、C++ 需要明确指定变量数据类型,这种叫强类型定义语言。有的语言(主要是脚本语言),如 Javascript、Shell 等,不需要明确指定数据类型,这种叫弱类型定义语言。
还需要注意的一点是变量的作用域范围和生命周期。不同语言变量的作用域范围和生命周期不一定一样,这个需要在代码中细细体会,有时会为此埋雷。
逻辑控制语句
编程语言都会有逻辑控制语句,哪怕是汇编语言。
掌握条件语句、循环语句、中断循环语句(break、continue)、选择语句。一般区别仅仅在于关键字、语法格式略有不同。
运算符
掌握基本运算符,如算术运算符、关系运算符、逻辑运算符、赋值运算符等。
有些语言还提供位运算符、特殊运算符,视情节掌握。
注释(没啥好说的)
函数
编程语言基本都有函数。注意语法格式:是否支持出参;支持哪些数据作为入参,有些语言允许将函数作为参数传入另一个参数(即回调);返回值;如何退出函数(如 Java、C++的 return,)。
数组、枚举、集合
枚举只有部分编程语言有,如 Java、C++、C#。
但是数组和集合(有些语言叫容器)一般编程语言都有,只是有的编程语言提供的集合比较丰富。使用方法基本类似。
常用类
比较常用的类(当然有些语言中不叫类,叫对象或者其他什么,这个不重要,领会精神)请了解其 API 用法,如:字符串、日期、数学计算等等。
语言特性
语言特性这个特字反映的就是各个编程语言自身的”独特个性”,这涉及的点比较多,简单列举一些。
编程模式
比较流行的编程模式大概有:
面向对象编程,主要是封装、继承、多态;函数式编程,主要是应用 Lambda;过程式编程,可以理解为实现需求功能的特定步骤。
每种编程模式都有一定的道理,我从不认为只有面向对象编程才是王道。
Java 是面向对象语言,从 Java8 开始也支持函数编程(引入 Lambda 表达式);C++ 可以算是半面向对象,半面向过程式语言。
语言自身特性
每个语言自身都有一些重要特性需要了解。例如,学习 C、C++,你必须了解内存的申请和释放,了解指针、引用。而学习 Java,你需要了解 JVM,垃圾回收机制。学习 Javascript,你需要了解 DOM 操作等。
代码组织、模块加载、库管理
一个程序一般都有很多个源代码文件。这就会引入这些问题:如何将代码文件组织起来?如何根据业务需要,选择将部分模块启动时进行加载,部分模块使用懒加载(或者热加载)?
最基本的引用文件就不提了,如 C、C++的#include,Java 的 import 等。
针对代码组织、模块加载、库管理这些问题,不同语言会有不同的解决方案。
如 Java 可以用 maven、gradle 管理项目依赖、组织代码结构;Javascript (包括 Nodejs、jquery、react 等等库)可以用 npm、yarn 管理依赖,用 webpack 等工具管理模块加载。
容错处理
程序总难免会有 bug。
所以为了代码健壮性也好,为了方便定位问题也好,代码中需要有容错处理。常见的手段有:
- 异常
- 断言
- 日志
- 调试
- 单元测试
输入输出和文件处理
这块知识比较繁杂。建议提纲挈领的学习一下,理解基本概念,比如输入输出流、管道等等。至于 API,用到的时候再查一下即可。
回调机制
每种语言实现回调的方式有所不同,如 .Net 的 delegate (大量被用于 WinForm 程序);Javascript 中函数天然支持回调:Javascript 函数允许传入另一个函数作为入参,然后在方法中调用它。其它语言的回调方式不一一列举。
序列化和反序列化
首先需要了解的是,序列化和反序列化的作用是为了在不同平台之间传输对象。
其次,要知道序列化存在多种方式,不同编程语言可能有多种方案。根据应用的序列化方式,选择性了解即可。
进阶特性
以下学习内容属于进阶性内容。可以根据开发需要去学习、掌握。需要注意的是,学习这些特性的态度应该是不学则已,学则死磕。因为半懂半不懂,特别容易引入问题。
对于半桶水的同学,我想说:放过自己,也放过别人,活着不好吗?
并发编程:好处多多,十分重要,但是并发代码容易出错,且出错难以定位。要学习还是要花很大力气的,需要了解大量知识,如:进程、线程、同步、异步、读写锁等等。
反射 - 让你可以动态编程(慎用)。
泛型 - 集合(或者叫容器)的基石。精通泛型,能大大提高你的代码效率。
元数据 - 描述数据的数据。Java 中叫做注解。
库和框架
学习一门编程语言,难免需要用到围绕它构建的技术生态圈——库和框架。这方面知识范围太庞大,根据实际应用领域去学习吧。比如搞 JavaWeb,你多多少少肯定要用到 Spring、Mybatis、Hibernate、Shiro 等大量开发框架;如果做 Javascript 前端,你可能会用到 React、Vue、Angular 、jQuery 等库或框架。
小结
总结以上,编程语言学习的道路是任重而道远的,未来是光明的。
最后一句话与君共勉:路漫漫兮其修远,吾将上下而求索。
Laravel 5.5 入门指南
细读 Laravel5.5 文档:安装与配置
PHP 源码编程规范
在学习 TIPI 项目第二节介绍根目录文件时,第一个文件便是 CODING_STANDARDS ,遂翻译学习下官方给出的 PHP 源码代码规范。
Git 版本控制工具
一、Git 简介
Git 是什么
Git 是一个开源的分布式版本控制系统。
什么是版本控制
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。
什么是分布式版本控制系统
介绍分布式版本控制系统前,有必要先了解一下传统的集中式版本控制系统。
集中化的版本控制系统,诸如 CVS,Subversion 等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。
这么做最显而易见的缺点是中央服务器的单点故障。如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。要是中央服务器的磁盘发生故障,碰巧没做备份,或者备份不够及时,就会有丢失数据的风险。最坏的情况是彻底丢失整个项目的所有历史更改记录。
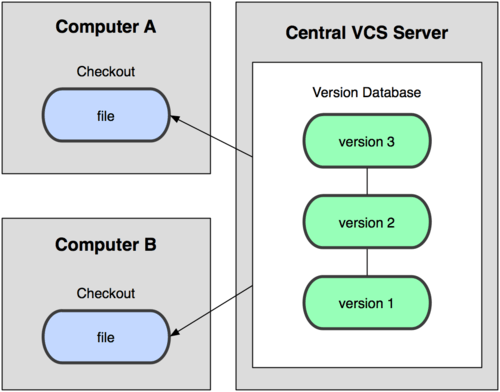
分布式版本控制系统的客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。因为每一次的提取操作,实际上都是一次对代码仓库的完整备份。
为什么使用 Git
Git 是分布式的。这是 Git 和其它非分布式的版本控制系统,例如 svn,cvs 等,最核心的区别。分布式带来以下好处:
- 工作时不需要联网 - 首先,分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件 A,你的同事也在他的电脑上改了文件 A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
- 更加安全
- 集中式版本控制系统,一旦中央服务器出了问题,所有人都无法工作。
- 分布式版本控制系统,每个人电脑中都有完整的版本库,所以某人的机器挂了,并不影响其它人。
二、Git 安装配置
安装
Debian/Ubuntu 环境安装
如果你使用的系统是 Debian/Ubuntu , 安装命令为:
1 | apt-get install libcurl4-gnutls-dev libexpat1-dev gettext \ |
Centos/RedHat 环境安装
如果你使用的系统是 Centos/RedHat ,安装命令为:
1 | yum install curl-devel expat-devel gettext-devel \ |
Windows 环境安装
在Git 官方下载地址下载 exe 安装包。按照安装向导安装即可。
建议安装 Git Bash 这个 git 的命令行工具。
Mac 环境安装
在Git 官方下载地址下载 mac 安装包。按照安装向导安装即可。
配置
Git 自带一个 git config 的工具来帮助设置控制 Git 外观和行为的配置变量。 这些变量存储在三个不同的位置:
/etc/gitconfig文件: 包含系统上每一个用户及他们仓库的通用配置。 如果使用带有--system选项的git config时,它会从此文件读写配置变量。~/.gitconfig或~/.config/git/config文件:只针对当前用户。 可以传递--global选项让 Git 读写此文件。- 当前使用仓库的 Git 目录中的
config文件(就是.git/config):针对该仓库。
每一个级别覆盖上一级别的配置,所以 .git/config 的配置变量会覆盖 /etc/gitconfig 中的配置变量。
在 Windows 系统中,Git 会查找 $HOME 目录下(一般情况下是 C:\Users\$USER)的 .gitconfig 文件。 Git 同样也会寻找 /etc/gitconfig 文件,但只限于 MSys 的根目录下,即安装 Git 时所选的目标位置。
用户信息
当安装完 Git 应该做的第一件事就是设置你的用户名称与邮件地址。 这样做很重要,因为每一个 Git 的提交都会使用这些信息,并且它会写入到你的每一次提交中,不可更改:
1 | git config --global user.name "John Doe" |
再次强调,如果使用了 --global 选项,那么该命令只需要运行一次,因为之后无论你在该系统上做任何事情, Git 都会使用那些信息。 当你想针对特定项目使用不同的用户名称与邮件地址时,可以在那个项目目录下运行没有 --global 选项的命令来配置。
很多 GUI 工具都会在第一次运行时帮助你配置这些信息。
.gitignore
.gitignore 文件可能从字面含义也不难猜出:这个文件里配置的文件或目录,会自动被 git 所忽略,不纳入版本控制。
在日常开发中,我们的项目经常会产生一些临时文件,如编译 Java 产生的 *.class 文件,又或是 IDE 自动生成的隐藏目录(Intellij 的 .idea 目录、Eclipse 的 .settings 目录等)等等。这些文件或目录实在没必要纳入版本管理。在这种场景下,你就需要用到 .gitignore 配置来过滤这些文件或目录。
配置的规则很简单,也没什么可说的,看几个例子,自然就明白了。
这里推荐一下 Github 的开源项目:gitignore
在这里,你可以找到很多常用的模板,如:Java、Nodejs、C++ 的 .gitignore 模板等等。
三、Git 原理
个人认为,对于 Git 这个版本工具,再不了解原理的情况下,直接去学习命令行,可能会一头雾水。所以,本文特意将原理放在命令使用章节之前讲解。
版本库
当你一个项目到本地或创建一个 git 项目,项目目录下会有一个隐藏的 .git 子目录。这个目录是 git 用来跟踪管理版本库的,千万不要手动修改。
哈希值
Git 中所有数据在存储前都计算校验和,然后以校验和来引用。 这意味着不可能在 Git 不知情时更改任何文件内容或目录内容。 这个功能建构在 Git 底层,是构成 Git 哲学不可或缺的部分。 若你在传送过程中丢失信息或损坏文件,Git 就能发现。
Git 用以计算校验和的机制叫做 SHA-1 散列(hash,哈希)。 这是一个由 40 个十六进制字符(0-9 和 a-f)组成字符串,基于 Git 中文件的内容或目录结构计算出来。 SHA-1 哈希看起来是这样:
1 | 24b9da6552252987aa493b52f8696cd6d3b00373 |
Git 中使用这种哈希值的情况很多,你将经常看到这种哈希值。 实际上,Git 数据库中保存的信息都是以文件内容的哈希值来索引,而不是文件名。
文件状态
在 GIt 中,你的文件可能会处于三种状态之一:
- 已修改(modified) - 已修改表示修改了文件,但还没保存到数据库中。
- 已暂存(staged) - 已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
- 已提交(committed) - 已提交表示数据已经安全的保存在本地数据库中。
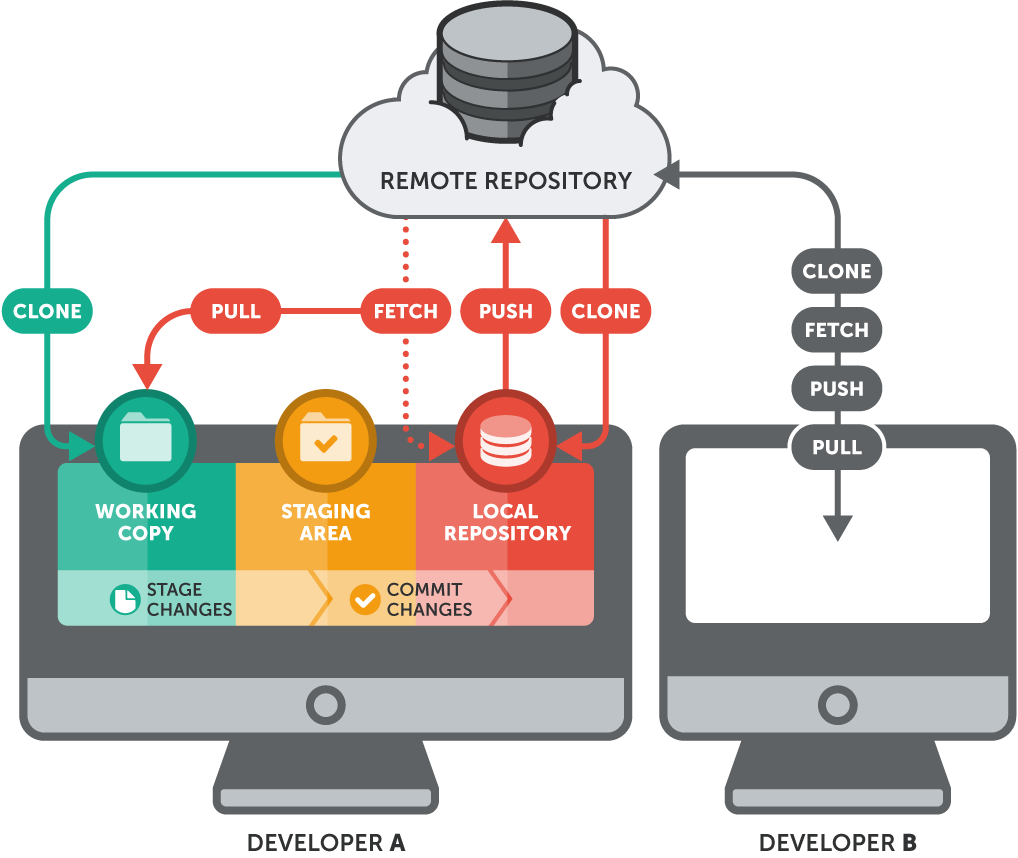
工作区域
与文件状态对应的,不同状态的文件在 Git 中处于不同的工作区域。
- 工作区(working) - 当你
git clone一个项目到本地,相当于在本地克隆了项目的一个副本。工作区是对项目的某个版本独立提取出来的内容。 这些从 Git 仓库的压缩数据库中提取出来的文件,放在磁盘上供你使用或修改。 - 暂存区(staging) - 暂存区是一个文件,保存了下次将提交的文件列表信息,一般在 Git 仓库目录中。 有时候也被称作`‘索引’’,不过一般说法还是叫暂存区。
- 本地仓库(local) - 提交更新,找到暂存区域的文件,将快照永久性存储到 Git 本地仓库。
- 远程仓库(remote) - 以上几个工作区都是在本地。为了让别人可以看到你的修改,你需要将你的更新推送到远程仓库。同理,如果你想同步别人的修改,你需要从远程仓库拉取更新。
四、Git 命令
国外网友制作了一张 Git Cheat Sheet,总结很精炼,各位不妨收藏一下。
本节选择性介绍 git 中比较常用的命令行场景。
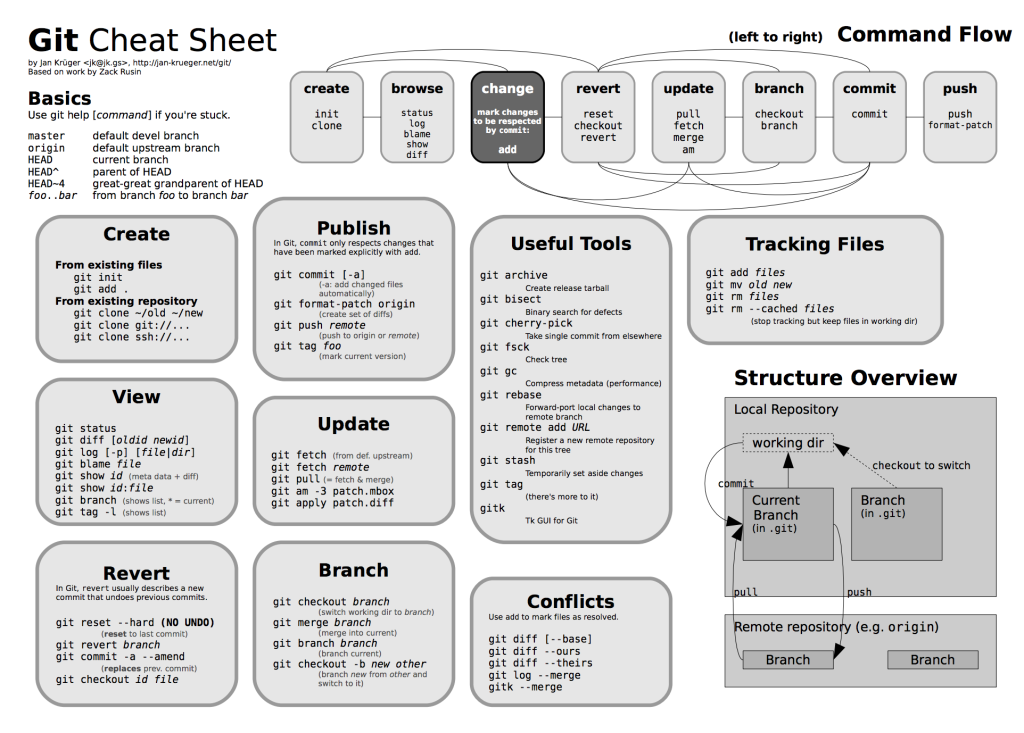
创建仓库
克隆一个已创建的仓库:
1 | 通过 SSH |
创建一个新的本地仓库:
1 | git init |
添加修改
添加修改到暂存区:
1 | 把指定文件添加到暂存区 |
提交修改到本地仓库:
1 | 提交本地的所有修改 |
储藏
有时,我们需要在同一个项目的不同分支上工作。当需要切换分支时,偏偏本地的工作还没有完成,此时,提交修改显得不严谨,但是不提交代码又无法切换分支。这时,你可以使用 git stash 将本地的修改内容作为草稿储藏起来。
官方称之为储藏,但我个人更喜欢称之为存草稿。
1 | 1. 将修改作为当前分支的草稿保存 |
撤销修改
撤销本地修改:
1 | 移除缓存区的所有文件(i.e. 撤销上次git add) |
删除添加.gitignore文件前错误提交的文件:
1 | 提交一条 git 记录,提交信息为 remove xyz file |
撤销远程修改(创建一个新的提交,并回滚到指定版本):
1 | revert 哈希号为 commit-hash 的记录 |
彻底删除指定版本:
1 | 执行下面命令后,commit-hash 提交后的记录都会被彻底删除,使用需谨慎 |
更新与推送
更新:
1 | 下载远程端版本,但不合并到HEAD中 |
推送:
1 | 将本地版本推送到远程端 |
查看信息
显示工作路径下已修改的文件:git status
显示与上次提交版本文件的不同:git diff
显示提交历史:
1 | 从最新提交开始,显示所有的提交记录(显示hash, 作者信息,提交的标题和时间) |
显示搜索内容:
1 | 从当前目录的所有文件中查找文本内容 |
分支
增删查分支:
1 | 列出所有的分支 |
切换分支:
1 | 切换分支 |
标签
1 | 给当前版本打标签 |
合并与重置
merge 与 rebase 虽然是 git 常用功能,但是强烈建议不要使用 git 命令来完成这项工作。
因为如果出现代码冲突,在没有代码比对工具的情况下,实在太艰难了。
你可以考虑使用各种 Git GUI 工具。
合并:
1 | 将分支合并到当前HEAD中 |
重置:
1 | 将当前HEAD版本重置到分支中,请勿重置已发布的提交 |
Github
Github 作为最著名的代码开源协作社区,在程序员圈想必无人不知,无人不晓。
这里不赘述 Github 的用法,确实有不会用的新手同学,可以参考 官方教程。
clone 方式
Git 支持三种协议:HTTPS / SSH / GIT
而 Github 上支持 HTTPS 和 SSH。
HTTPS 这种方式要求你每次 push 时都要输入用户名、密码,有些繁琐。
而 SSH 要求你本地生成证书,然后在你的 Github 账户中注册。第一次配置麻烦是麻烦了点,但是以后就免去了每次 push 需要输入用户名、密码的繁琐。

以下介绍以下,如何生成证书,以及在 Github 中注册。
生成 SSH 公钥
如前所述,许多 Git 服务器都使用 SSH 公钥进行认证。 为了向 Git 服务器提供 SSH 公钥,如果某系统用户尚未拥有密钥,必须事先为其生成一份。 这个过程在所有操作系统上都是相似的。 首先,你需要确认自己是否已经拥有密钥。 默认情况下,用户的 SSH 密钥存储在其 \~/.ssh 目录下。 进入该目录并列出其中内容,你便可以快速确认自己是否已拥有密钥:
1 | cd ~/.ssh |
我们需要寻找一对以 id_dsa 或 id_rsa 命名的文件,其中一个带有 .pub 扩展名。 .pub 文件是你的公钥,另一个则是私钥。 如果找不到这样的文件(或者根本没有 .ssh 目录),你可以通过运行 ssh-keygen 程序来创建它们。在 Linux/Mac 系统中,ssh-keygen 随 SSH 软件包提供;在 Windows 上,该程序包含于 MSysGit 软件包中。
1 | ssh-keygen |
首先 ssh-keygen 会确认密钥的存储位置(默认是 .ssh/id_rsa),然后它会要求你输入两次密钥口令。如果你不想在使用密钥时输入口令,将其留空即可。
现在,进行了上述操作的用户需要将各自的公钥发送给任意一个 Git 服务器管理员(假设服务器正在使用基于公钥的 SSH 验证设置)。 他们所要做的就是复制各自的 .pub 文件内容,并将其通过邮件发送。 公钥看起来是这样的:
1 | cat ~/.ssh/id_rsa.pub |
在你的 Github 账户中,依次点击 Settings > SSH and GPG keys > New SSH key
然后,将上面生成的公钥内容粘贴到 Key 编辑框并保存。至此大功告成。
后面,你在克隆你的 Github 项目时使用 SSH 方式即可。
如果觉得我的讲解还不够细致,可以参考:adding-a-new-ssh-key-to-your-github-account
五、Git 最佳实践
详细内容,可以参考这篇文章:Git 在团队中的最佳实践–如何正确使用 Git Flow
Git 在实际开发中的最佳实践策略 Git Flow 可以归纳为以下:
master分支 - 也就是我们经常使用的主线分支,这个分支是最近发布到生产环境的代码,这个分支只能从其他分支合并,不能在这个分支直接修改。develop分支 - 这个分支是我们的主开发分支,包含所有要发布到下一个 release 的代码,这个分支主要是从其他分支合并代码过来,比如 feature 分支。feature分支 - 这个分支主要是用来开发一个新的功能,一旦开发完成,我们合并回 develop 分支进入下一个 release。release分支 - 当你需要一个发布一个新 release 的时候,我们基于 Develop 分支创建一个 release 分支,完成 release 后,我们合并到 master 和 develop 分支。hotfix分支 - 当我们在 master 发现新的 Bug 时候,我们需要创建一个 hotfix, 完成 hotfix 后,我们合并回 master 和 develop 分支,所以 hotfix 的改动会进入下一个 release。
六、Git FAQ
编辑提交(editting commits)
我刚才提交了什么
如果你用 git commit -a 提交了一次变化(changes),而你又不确定到底这次提交了哪些内容。 你就可以用下面的命令显示当前HEAD上的最近一次的提交(commit):
1 | git show |
或者
1 | git log -n1 -p |
我的提交信息(commit message)写错了
如果你的提交信息(commit message)写错了且这次提交(commit)还没有推(push), 你可以通过下面的方法来修改提交信息(commit message):
1 | git commit --amend |
这会打开你的默认编辑器, 在这里你可以编辑信息. 另一方面, 你也可以用一条命令一次完成:
1 | git commit --amend -m 'xxxxxxx' |
如果你已经推(push)了这次提交(commit), 你可以修改这次提交(commit)然后强推(force push), 但是不推荐这么做。
我提交(commit)里的用户名和邮箱不对
如果这只是单个提交(commit),修改它:
1 | git commit --amend --author "New Authorname <authoremail@mydomain.com>" |
如果你需要修改所有历史, 参考 ‘git filter-branch’的指南页.
我想从一个提交(commit)里移除一个文件
通过下面的方法,从一个提交(commit)里移除一个文件:
1 | git checkout HEAD^ myfile |
这将非常有用,当你有一个开放的补丁(open patch),你往上面提交了一个不必要的文件,你需要强推(force push)去更新这个远程补丁。
我想删除我的的最后一次提交(commit)
如果你需要删除推了的提交(pushed commits),你可以使用下面的方法。可是,这会不可逆的改变你的历史,也会搞乱那些已经从该仓库拉取(pulled)了的人的历史。简而言之,如果你不是很确定,千万不要这么做。
1 | git reset HEAD^ --hard |
如果你还没有推到远程, 把 Git 重置(reset)到你最后一次提交前的状态就可以了(同时保存暂存的变化):
1 | (my-branch*)$ git reset --soft HEAD@{1} |
这只能在没有推送之前有用. 如果你已经推了, 唯一安全能做的是 git revert SHAofBadCommit, 那会创建一个新的提交(commit)用于撤消前一个提交的所有变化(changes); 或者, 如果你推的这个分支是 rebase-safe 的 (例如: 其它开发者不会从这个分支拉), 只需要使用 git push -f; 更多, 请参考 the above section。
删除任意提交(commit)
同样的警告:不到万不得已的时候不要这么做.
1 | git rebase --onto SHA1_OF_BAD_COMMIT^ SHA1_OF_BAD_COMMIT |
或者做一个 交互式 rebase 删除那些你想要删除的提交(commit)里所对应的行。
我尝试推一个修正后的提交(amended commit)到远程,但是报错
1 | To https://github.com/yourusername/repo.git |
注意, rebasing(见下面)和修正(amending)会用一个新的提交(commit)代替旧的, 所以如果之前你已经往远程仓库上推过一次修正前的提交(commit),那你现在就必须强推(force push) (-f)。 注意 – 总是 确保你指明一个分支!
1 | git push origin mybranch -f |
一般来说, 要避免强推. 最好是创建和推(push)一个新的提交(commit),而不是强推一个修正后的提交。后者会使那些与该分支或该分支的子分支工作的开发者,在源历史中产生冲突。
我意外的做了一次硬重置(hard reset),我想找回我的内容
如果你意外的做了 git reset --hard, 你通常能找回你的提交(commit), 因为 Git 对每件事都会有日志,且都会保存几天。
1 | git reflog |
你将会看到一个你过去提交(commit)的列表, 和一个重置的提交。 选择你想要回到的提交(commit)的 SHA,再重置一次:
1 | git reset --hard SHA1234 |
这样就完成了。
暂存(Staging)
我需要把暂存的内容添加到上一次的提交(commit)
1 | (my-branch*)$ git commit --amend |
我想要暂存一个新文件的一部分,而不是这个文件的全部
一般来说, 如果你想暂存一个文件的一部分, 你可这样做:
1 | git add --patch filename.x |
-p 简写。这会打开交互模式, 你将能够用 s 选项来分隔提交(commit); 然而, 如果这个文件是新的, 会没有这个选择, 添加一个新文件时, 这样做:
1 | git add -N filename.x |
然后, 你需要用 e 选项来手动选择需要添加的行,执行 git diff --cached 将会显示哪些行暂存了哪些行只是保存在本地了。
我想把在一个文件里的变化(changes)加到两个提交(commit)里
git add 会把整个文件加入到一个提交. git add -p 允许交互式的选择你想要提交的部分.
我想把暂存的内容变成未暂存,把未暂存的内容暂存起来
这个有点困难, 我能想到的最好的方法是先 stash 未暂存的内容, 然后重置(reset),再 pop 第一步 stashed 的内容, 最后再 add 它们。
1 | git stash -k |
未暂存(Unstaged)的内容
我想把未暂存的内容移动到一个新分支
1 | git checkout -b my-branch |
我想把未暂存的内容移动到另一个已存在的分支
1 | git stash |
我想丢弃本地未提交的变化(uncommitted changes)
如果你只是想重置源(origin)和你本地(local)之间的一些提交(commit),你可以:
1 | # one commit |
重置某个特殊的文件, 你可以用文件名做为参数:
1 | git reset filename |
我想丢弃某些未暂存的内容
如果你想丢弃工作拷贝中的一部分内容,而不是全部。
签出(checkout)不需要的内容,保留需要的。
1 | git checkout -p |
另外一个方法是使用 stash, Stash 所有要保留下的内容, 重置工作拷贝, 重新应用保留的部分。
1 | git stash -p |
或者, stash 你不需要的部分, 然后 stash drop。
1 | git stash -p |
分支(Branches)
我从错误的分支拉取了内容,或把内容拉取到了错误的分支
这是另外一种使用 git reflog 情况,找到在这次错误拉(pull) 之前 HEAD 的指向。
1 | git reflog |
重置分支到你所需的提交(desired commit):
1 | git reset --hard c5bc55a |
完成。
我想扔掉本地的提交(commit),以便我的分支与远程的保持一致
先确认你没有推(push)你的内容到远程。
git status 会显示你领先(ahead)源(origin)多少个提交:
1 | git status |
一种方法是:
1 | git reset --hard origin/my-branch |
我需要提交到一个新分支,但错误的提交到了 master
在 master 下创建一个新分支,不切换到新分支,仍在 master 下:
1 | git branch my-branch |
把 master 分支重置到前一个提交:
1 | git reset --hard HEAD^ |
HEAD^ 是 HEAD^1 的简写,你可以通过指定要设置的HEAD来进一步重置。
或者, 如果你不想使用 HEAD^, 找到你想重置到的提交(commit)的 hash(git log 能够完成), 然后重置到这个 hash。 使用git push 同步内容到远程。
例如, master 分支想重置到的提交的 hash 为a13b85e:
1 | git reset --hard a13b85e |
签出(checkout)刚才新建的分支继续工作:
1 | git checkout my-branch |
我想保留来自另外一个 ref-ish 的整个文件
假设你正在做一个原型方案(原文为 working spike (see note)), 有成百的内容,每个都工作得很好。现在, 你提交到了一个分支,保存工作内容:
1 | git add -A && git commit -m "Adding all changes from this spike into one big commit." |
当你想要把它放到一个分支里 (可能是feature, 或者 develop), 你关心是保持整个文件的完整,你想要一个大的提交分隔成比较小。
假设你有:
- 分支
solution, 拥有原型方案, 领先develop分支。 - 分支
develop, 在这里你应用原型方案的一些内容。
我去可以通过把内容拿到你的分支里,来解决这个问题:
1 | git checkout solution -- file1.txt |
这会把这个文件内容从分支 solution 拿到分支 develop 里来:
1 | # On branch develop |
然后, 正常提交。
Note: Spike solutions are made to analyze or solve the problem. These solutions are used for estimation and discarded once everyone gets clear visualization of the problem. ~ Wikipedia.
我把几个提交(commit)提交到了同一个分支,而这些提交应该分布在不同的分支里
假设你有一个master分支, 执行git log, 你看到你做过两次提交:
1 | git log |
让我们用提交 hash(commit hash)标记 bug (e3851e8 for #21, 5ea5173 for #14).
首先, 我们把master分支重置到正确的提交(a13b85e):
1 | git reset --hard a13b85e |
现在, 我们对 bug #21 创建一个新的分支:
1 | git checkout -b 21 |
接着, 我们用 cherry-pick 把对 bug #21 的提交放入当前分支。 这意味着我们将应用(apply)这个提交(commit),仅仅这一个提交(commit),直接在 HEAD 上面。
1 | git cherry-pick e3851e8 |
这时候, 这里可能会产生冲突, 参见交互式 rebasing 章 冲突节 解决冲突.
再者, 我们为 bug #14 创建一个新的分支, 也基于master分支
1 | git checkout master |
最后, 为 bug #14 执行 cherry-pick:
1 | git cherry-pick 5ea5173 |
我想删除上游(upstream)分支被删除了的本地分支
一旦你在 github 上面合并(merge)了一个 pull request, 你就可以删除你 fork 里被合并的分支。 如果你不准备继续在这个分支里工作, 删除这个分支的本地拷贝会更干净,使你不会陷入工作分支和一堆陈旧分支的混乱之中。
1 | git fetch -p |
我不小心删除了我的分支
如果你定期推送到远程, 多数情况下应该是安全的,但有些时候还是可能删除了还没有推到远程的分支。 让我们先创建一个分支和一个新的文件:
1 | git checkout -b my-branch |
添加文件并做一次提交
1 | git add . |
现在我们切回到主(master)分支,‘不小心的’删除my-branch分支
1 | git checkout master |
在这时候你应该想起了reflog, 一个升级版的日志,它存储了仓库(repo)里面所有动作的历史。
1 | git reflog |
正如你所见,我们有一个来自删除分支的提交 hash(commit hash),接下来看看是否能恢复删除了的分支。
1 | git checkout -b my-branch-help |
看! 我们把删除的文件找回来了。 Git 的 reflog 在 rebasing 出错的时候也是同样有用的。
我想删除一个分支
删除一个远程分支:
1 | git push origin --delete my-branch |
你也可以:
1 | git push origin :my-branch |
删除一个本地分支:
1 | git branch -D my-branch |
我想从别人正在工作的远程分支签出(checkout)一个分支
首先, 从远程拉取(fetch) 所有分支:
1 | git fetch --all |
假设你想要从远程的daves分支签出到本地的daves
1 | git checkout --track origin/daves |
(--track 是 git checkout -b [branch] [remotename]/[branch] 的简写)
这样就得到了一个daves分支的本地拷贝, 任何推过(pushed)的更新,远程都能看到.
Rebasing 和合并(Merging)
我想撤销 rebase/merge
你可以合并(merge)或 rebase 了一个错误的分支, 或者完成不了一个进行中的 rebase/merge。 Git 在进行危险操作的时候会把原始的 HEAD 保存在一个叫 ORIG_HEAD 的变量里, 所以要把分支恢复到 rebase/merge 前的状态是很容易的。
1 | git reset --hard ORIG_HEAD |
我已经 rebase 过, 但是我不想强推(force push)
不幸的是,如果你想把这些变化(changes)反应到远程分支上,你就必须得强推(force push)。 是因你快进(Fast forward)了提交,改变了 Git 历史, 远程分支不会接受变化(changes),除非强推(force push)。这就是许多人使用 merge 工作流, 而不是 rebasing 工作流的主要原因之一, 开发者的强推(force push)会使大的团队陷入麻烦。使用时需要注意,一种安全使用 rebase 的方法是,不要把你的变化(changes)反映到远程分支上, 而是按下面的做:
1 | git checkout my-branch |
更多, 参见 this SO thread.
我需要组合(combine)几个提交(commit)
假设你的工作分支将会做对于 master 的 pull-request。 一般情况下你不关心提交(commit)的时间戳,只想组合 所有 提交(commit) 到一个单独的里面, 然后重置(reset)重提交(recommit)。 确保主(master)分支是最新的和你的变化都已经提交了, 然后:
1 | git reset --soft master |
如果你想要更多的控制, 想要保留时间戳, 你需要做交互式 rebase (interactive rebase):
1 | git rebase -i master |
如果没有相对的其它分支, 你将不得不相对自己的HEAD 进行 rebase。 例如:你想组合最近的两次提交(commit), 你将相对于HEAD\~2 进行 rebase, 组合最近 3 次提交(commit), 相对于HEAD\~3, 等等。
1 | git rebase -i HEAD~2 |
在你执行了交互式 rebase 的命令(interactive rebase command)后, 你将在你的编辑器里看到类似下面的内容:
1 | pick a9c8a1d Some refactoring |
所有以 # 开头的行都是注释, 不会影响 rebase.
然后,你可以用任何上面命令列表的命令替换 pick, 你也可以通过删除对应的行来删除一个提交(commit)。
例如, 如果你想 单独保留最旧(first)的提交(commit),组合所有剩下的到第二个里面, 你就应该编辑第二个提交(commit)后面的每个提交(commit) 前的单词为 f:
1 | pick a9c8a1d Some refactoring |
如果你想组合这些提交(commit) 并重命名这个提交(commit), 你应该在第二个提交(commit)旁边添加一个r,或者更简单的用s 替代 f:
1 | pick a9c8a1d Some refactoring |
你可以在接下来弹出的文本提示框里重命名提交(commit)。
1 | Newer, awesomer features |
如果成功了, 你应该看到类似下面的内容:
1 | Successfully rebased and updated refs/heads/master. |
安全合并(merging)策略
--no-commit 执行合并(merge)但不自动提交, 给用户在做提交前检查和修改的机会。 no-ff 会为特性分支(feature branch)的存在过留下证据, 保持项目历史一致。
1 | git merge --no-ff --no-commit my-branch |
我需要将一个分支合并成一个提交(commit)
1 | git merge --squash my-branch |
我只想组合(combine)未推的提交(unpushed commit)
有时候,在将数据推向上游之前,你有几个正在进行的工作提交(commit)。这时候不希望把已经推(push)过的组合进来,因为其他人可能已经有提交(commit)引用它们了。
1 | git rebase -i @{u} |
这会产生一次交互式的 rebase(interactive rebase), 只会列出没有推(push)的提交(commit), 在这个列表时进行 reorder/fix/squash 都是安全的。
检查是否分支上的所有提交(commit)都合并(merge)过了
检查一个分支上的所有提交(commit)是否都已经合并(merge)到了其它分支, 你应该在这些分支的 head(或任何 commits)之间做一次 diff:
1 | git log --graph --left-right --cherry-pick --oneline HEAD...feature/120-on-scroll |
这会告诉你在一个分支里有而另一个分支没有的所有提交(commit), 和分支之间不共享的提交(commit)的列表。 另一个做法可以是:
1 | git log master ^feature/120-on-scroll --no-merges |
交互式 rebase(interactive rebase)可能出现的问题
这个 rebase 编辑屏幕出现’noop’
如果你看到的是这样:
1 | noop |
这意味着你 rebase 的分支和当前分支在同一个提交(commit)上, 或者 领先(ahead) 当前分支。 你可以尝试:
- 检查确保主(master)分支没有问题
- rebase
HEAD\~2或者更早
有冲突的情况
如果你不能成功的完成 rebase, 你可能必须要解决冲突。
首先执行 git status 找出哪些文件有冲突:
1 | git status |
在这个例子里面, README.md 有冲突。 打开这个文件找到类似下面的内容:
1 | <<<<<<< HEAD |
你需要解决新提交的代码(示例里, 从中间==线到new-commit的地方)与HEAD 之间不一样的地方.
有时候这些合并非常复杂,你应该使用可视化的差异编辑器(visual diff editor):
1 | (master*)$ git mergetool -t opendiff |
在你解决完所有冲突和测试过后, git add 变化了的(changed)文件, 然后用git rebase --continue 继续 rebase。
1 | git add README.md |
如果在解决完所有的冲突过后,得到了与提交前一样的结果, 可以执行git rebase --skip。
任何时候你想结束整个 rebase 过程,回来 rebase 前的分支状态, 你可以做:
1 | git rebase --abort |
杂项(Miscellaneous Objects)
克隆所有子模块
1 | git clone --recursive git://github.com/foo/bar.git |
如果已经克隆了:
1 | git submodule update --init --recursive |
删除标签(tag)
1 | git tag -d <tag_name> |
恢复已删除标签(tag)
如果你想恢复一个已删除标签(tag), 可以按照下面的步骤: 首先, 需要找到无法访问的标签(unreachable tag):
1 | git fsck --unreachable | grep tag |
记下这个标签(tag)的 hash,然后用 Git 的 update-ref:
1 | git update-ref refs/tags/<tag_name> <hash> |
这时你的标签(tag)应该已经恢复了。
已删除补丁(patch)
如果某人在 GitHub 上给你发了一个 pull request, 但是然后他删除了他自己的原始 fork, 你将没法克隆他们的提交(commit)或使用 git am。在这种情况下, 最好手动的查看他们的提交(commit),并把它们拷贝到一个本地新分支,然后做提交。
做完提交后, 再修改作者,参见变更作者。 然后, 应用变化, 再发起一个新的 pull request。
跟踪文件(Tracking Files)
我只想改变一个文件名字的大小写,而不修改内容
1 | git mv --force myfile MyFile |
我想从 Git 删除一个文件,但保留该文件
1 | git rm --cached log.txt |
配置(Configuration)
我想给一些 Git 命令添加别名(alias)
在 OS X 和 Linux 下, 你的 Git 的配置文件储存在 \~/.gitconfig。我在[alias] 部分添加了一些快捷别名(和一些我容易拼写错误的),如下:
1 | [alias] |
我想缓存一个仓库(repository)的用户名和密码
你可能有一个仓库需要授权,这时你可以缓存用户名和密码,而不用每次推/拉(push/pull)的时候都输入,Credential helper 能帮你。
1 | git config --global credential.helper cache |
1 | git config --global credential.helper 'cache --timeout=3600' |
我不知道我做错了些什么
你把事情搞砸了:你 重置(reset) 了一些东西, 或者你合并了错误的分支, 亦或你强推了后找不到你自己的提交(commit)了。有些时候, 你一直都做得很好, 但你想回到以前的某个状态。
这就是 git reflog 的目的, reflog 记录对分支顶端(the tip of a branch)的任何改变, 即使那个顶端没有被任何分支或标签引用。基本上, 每次 HEAD 的改变, 一条新的记录就会增加到reflog。遗憾的是,这只对本地分支起作用,且它只跟踪动作 (例如,不会跟踪一个没有被记录的文件的任何改变)。
1 | git reflog |
上面的 reflog 展示了从 master 分支签出(checkout)到 2.2 分支,然后再签回。 那里,还有一个硬重置(hard reset)到一个较旧的提交。最新的动作出现在最上面以 HEAD@{0}标识.
如果事实证明你不小心回移(move back)了提交(commit), reflog 会包含你不小心回移前 master 上指向的提交(0254ea7)。
1 | git reset --hard 0254ea7 |
然后使用 git reset 就可以把 master 改回到之前的 commit,这提供了一个在历史被意外更改情况下的安全网。
参考资料
- 官方资源
- 模板
- gitignore 模板 - .gitignore 文件模板
- gitattributes 模板 - .gitattributes 文件模板
- github-cheat-sheet - git 命令简略图表
- Git 书
- Git 官方推荐教程 - Scott Chacon 的 Git 书。
- Git 教程
- 文章
- Git 工具
- guis - Git 官网展示的客户端工具列表。
- gogs - 极易搭建的自助 Git 服务。
- gitflow 模型的工具。
- firstaidgit.io 一个可搜索的最常被问到的 Git 的问题
- git-extra-commands - 一堆有用的额外的 Git 脚本
- git-extras - GIT 工具集 – repo summary, repl, changelog population, author commit percentages and more
- git-fire。
- git-tips - Git 小提示
- git-town - 通用,高级 Git 工作流支持!
- GUI 客户端(GUI Clients)
- git cheat sheet
软件工程入门指南
软件工程入门指南
📦 本文已归档到:「blog」
软件工程是一门研究用工程化方法构建和维护有效的、实用的和高质量的软件的学科。它涉及程序设计语言、数据库、软件开发工具、系统平台、标准、设计模式等方面。
[TOC]
软件工程的目标
软件工程的目标是:在给定成本、进度的前提下,开发出具有适用性、有效性、可修改性、可靠性、可理解性、可维护性、可重用性、可移植性、可追踪性、可互操作性和满足用户需求的软件产品。
- 适用性 - 软件在不同的系统约束条件下,使用户需求得到满足的难易程度。
- 有效性 - 软件系统能最有效的利用计算机的时间和空间资源。各种软件无不把系统的时/空开销作为衡量软件质量的一项重要技术指标。很多场合,在追求时间有效性和空间有效性时会发生矛盾,这时不得不牺牲时间有效性换取空间有效性或牺牲空间有效性换取时间有效性。时/空折衷是经常采用的技巧。
- 可修改性 - 允许对系统进行修改而不增加原系统的复杂性。它支持软件的调试和维护,是一个难以达到的目标。
- 可靠性 - 能防止因概念、设计和结构等方面的不完善造成的软件系统失效,具有挽回因操作不当造成软件系统失效的能力。
- 可理解性 - 系统具有清晰的结构,能直接反映问题的需求。可理解性有助于控制系统软件复杂性,并支持软件的维护、移植或重用。
- 可维护性 - 软件交付使用后,能够对它进行修改,以改正潜伏的错误,改进性能和其它属性,使软件产品适应环境的变化等。软件维护费用在软件开发费用中占有很大的比重。可维护性是软件工程中一项十分重要的目标。
- 可重用性 - 把概念或功能相对独立的一个或一组相关模块定义为一个软部件。可组装在系统的任何位置,降低工作量。
- 可移植性 - 软件从一个计算机系统或环境搬到另一个计算机系统或环境的难易程度。
- 可追踪性 - 根据软件需求对软件设计、程序进行正向追踪,或根据软件设计、程序对软件需求的逆向追踪的能力。
- 可互操作性 - 多个软件元素相互通信并协同完成任务的能力。
软件工程的原理
软件工程的七条基本原理:
- 用分阶段的生存周期计划进行严格的管理。
- 坚持进行阶段评审。
- 实行严格的产品控制。
- 采用现代程序设计技术。
- 软件工程结果应能清楚地审查。
- 开发小组的人员应该少而精。
- 承认不断改进软件工程实践的必要性。
软件工程的方法
著名的重量级开发方法:
- ISO9000 - ISO 9000 系列标准是国际标准化组织设立的标准,与品质管理系统有关。
- 能力成熟度模型(CMM) - CMM 涵盖一个成熟的软件发展组织所应具备的重要功能与项目,它描述了软件发展的演进过程,从毫无章法、不成熟的软件开发阶段到成熟软件开发阶段的过程。
- 统一软件开发过程(RUP) - RUP 是一种软件工程方法,为迭代式软件开发流程。
著名的轻量级开发方法:
- 敏捷开发(Agile Development) - 是一种应对快速变化的需求的一种软件开发能力。它们的具体名称、理念、过程、术语都不尽相同,相对于“非敏捷”,更强调程序员团队与业务专家之间的紧密协作、面对面的沟通(认为比书面的文档更有效)、频繁交付新的软件版本、紧凑而自我组织型的团队、能够很好地适应需求变化的代码编写和团队组织方法,也更注重软件开发过程中人的作用。
- 极限编程(XP) - 极限编程是敏捷软件开发中最有成效的方法学之一。极限编程技术以沟通(Communication)、简单(Simplicity)、反馈(Feedback)、勇气(Courage)和尊重(Respect)为价值标准。
软件需求
软件需求包括三个不同的层次:业务需求、用户需求和功能需求。
业务需求(Business requirement)表示组织或客户高层次的目标。业务需求通常来自项目投资人、购买产品的客户、实际用户的管理者、市场营销部门或产品策划部门。业务需求描述了组织为什么要开发一个系统,即组织希望达到的目标。使用前景和范围( vision and scope )文档来记录业务需求,这份文档有时也被称作项目轮廓图或市场需求( project charter 或 market requirement )文档。
用户需求(user requirement)描述的是用户的目标,或用户要求系统必须能完成的任务。用例、场景描述和事件――响应表都是表达用户需求的有效途径。也就是说用户需求描述了用户能使用系统来做些什么。
功能需求(functional requirement)规定开发人员必须在产品中实现的软件功能,用户利用这些功能来完成任务,满足业务需求。功能需求有时也被称作行为需求( behavioral requirement ),因为习惯上总是用“应该”对其进行描述:“系统应该发送电子邮件来通知用户已接受其预定”。功能需求描述是开发人员需要实现什么。
系统需求(system requirement)用于描述包含多个子系统的产品(即系统)的顶级需求。系统可以只包含软件系统,也可以既包含软件又包含硬件子系统。人也可以是系统的一部分,因此某些系统功能可能要由人来承担。
软件需求说明书( SRS )
软件需求说明书( SRS )完整地描述了软件系统的预期特性。开发、测试、质量保证、项目管理和其他相关的项目功能都要用到 SRS 。
除了功能需求外, SRS 中还包含非功能需求,包括性能指标和对质量属性的描述。
- 质量属性(quality attribute)对产品的功能描述作了补充,它从不同方面描述了产品的各种特性。这些特性包括可用性、可移植性、完整性、效率和健壮性,它们对用户或开发人员都很重要。其他的非功能需求包括系统与外部世界的外部界面,以及对设计与实现的约束。
- 约束(constraint)限制了开发人员设计和构建系统时的选择范围。
软件生命周期
软件生命周期(Software Life Cycle,SLC)是软件的产生直到报废或停止使用的生命周期。
- 问题定义 - 要求系统分析员与用户进行交流,弄清“用户需要计算机解决什么问题”然后提出关于“系统目标与范围的说明”,提交用户审查和确认。
- 可行性研究 - 一方面在于把待开发的系统的目标以明确的语言描述出来;另一方面从经济、技术、法律等多方面进行可行性分析。
- 需求分析 - 弄清用户对软件系统的全部需求,编写需求规格说明书和初步的用户手册,提交评审。
- 开发阶段
- 概要设计
- 详细设计
- 编码实现
- 软件测试 - 测试的过程分单元测试、组装测试以及系统测试三个阶段进行。测试的方法主要有白盒测试和黑盒测试两种。
- 维护
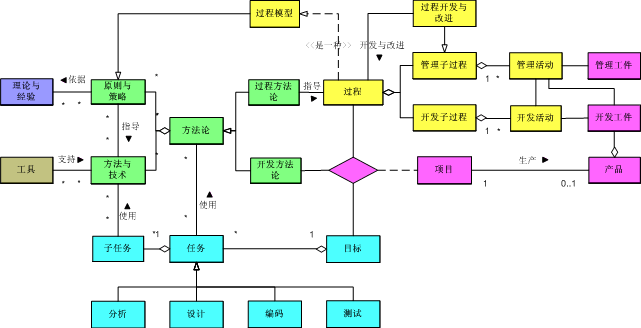
软件生命周期模型
瀑布模型
瀑布模型(Waterfall Model)强调系统开发应有完整的周期,且必须完整的经历周期的每一开发阶段,并系统化的考量分析与设计的技术、时间与资源之投入等。
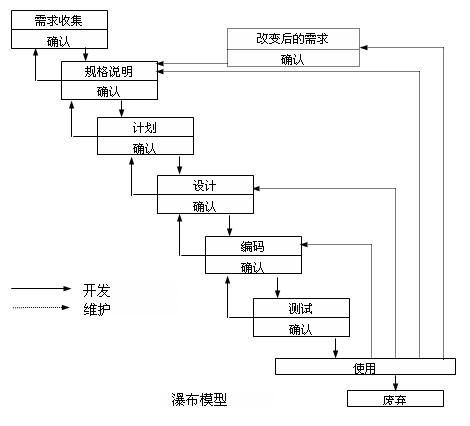
瀑布模型思想
瀑布模型核心思想是按工序将问题拆分,将功能的实现与设计分开,便于分工协作,即采用结构化的分析与设计方法将逻辑实现与物理实现分开。将软件生命周期划分为制定计划、需求分析、软件设计、程序编写、软件测试和运行维护等六个基本活动,并且规定了它们自上而下、相互衔接的固定次序,如同瀑布流水,逐级下落。
瀑布模型特点
优点:
- 为项目提供了按阶段划分的检查点。
- 当前一阶段完成后,您只需要去关注后续阶段。
- 可在迭代模型中应用瀑布模型。
- 它提供了一个模板,这个模板使得分析、设计、编码、测试和支持的方法可以在该模板下有一个共同的指导。
缺点:
- 各个阶段的划分完全固定,阶段之间产生大量的文档,极大地增加了工作量。
- 由于开发模型是线性的,用户只有等到整个过程的末期才能见到开发成果,从而增加了开发风险。
- 通过过多的强制完成日期和里程碑来跟踪各个项目阶段。
- 瀑布模型的突出缺点是不适应用户需求的变化。
适用场景:
是否使用这一模型主要取决于是否能理解客户的需求以及在项目的进程中这些需求的变化程度。对于需求经常变化的项目,不要适用瀑布模型。
螺旋模型
螺旋模型基本做法是在“瀑布模型”的每一个开发阶段前引入一个非常严格的风险识别、风险分析和风险控制,它把软件项目分解成一个个小项目。每个小项目都标识一个或多个主要风险,直到所有的主要风险因素都被确定。
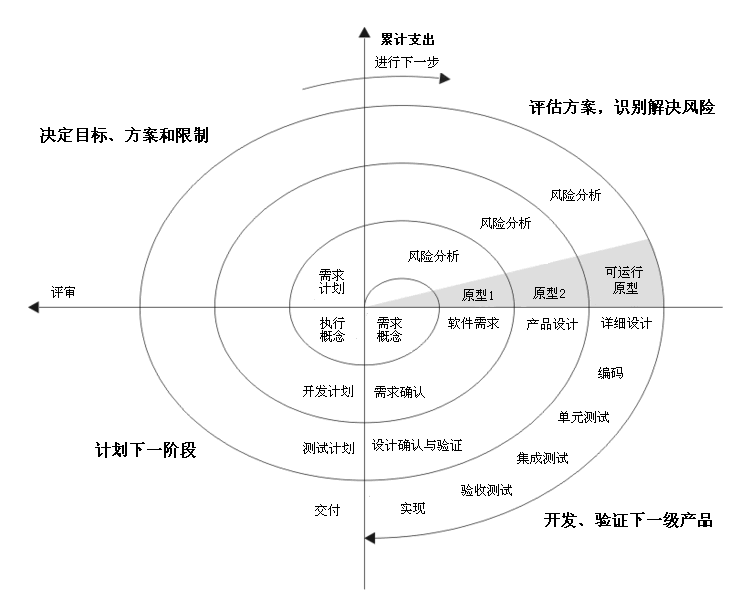
螺旋模型思想
螺旋模型沿着螺线进行若干次迭代,图中的四个象限代表了以下活动:
- 制定计划 - 确定软件目标,选定实施方案,弄清项目开发的限制条件;
- 风险分析 - 分析评估所选方案,考虑如何识别和消除风险;
- 实施工程 - 实施软件开发和验证;
- 客户评估 - 评价开发工作,提出修正建议,制定下一步计划。
螺旋模型由风险驱动,强调可选方案和约束条件从而支持软件的重用,有助于将软件质量作为特殊目标融入产品开发之中。
螺旋模型特点
优点:
- 设计上的灵活性,可以在项目的各个阶段进行变更。
- 以小的分段来构建大型系统,使成本计算变得简单容易。
- 客户始终参与每个阶段的开发,保证了项目不偏离正确方向以及项目的可控性。
- 随着项目推进,客户始终掌握项目的最新信息, 从而他或她能够和管理层有效地交互。
- 客户认可这种公司内部的开发方式带来的良好的沟通和高质量的产品。
缺点:
很难让用户确信这种演化方法的结果是可以控制的。建设周期长,而软件技术发展比较快,所以经常出现软件开发完毕后,和当前的技术水平有了较大的差距,无法满足当前用户需求。
适用场景:
对于新项目,需求不明确的情况下,适合用螺旋模型进行开发,便于风险控制和需求变更。
软件工程术语
- 里程碑(Milestone) - 在制定项目进度计划时,在进度时间表上设立一些重要的时间检查点,这样一来,就可以在项目执行过程中利用这些重要的时间检查点来对项目的进程进行检查和控制。这些重要的时间检查点被称作项目的里程碑。
- 人月 - 软件开发的工作量单位。如 200 人月,10 个人开发,那算来就是花 20 个月就可完工。
- 基线 - 基线是项目储存库中每个工件版本在特定时期的一个“快照”。它提供一个正式标准,随后的工作基于此标准,并且只有经过授权后才能变更这个标准。建立一个初始基线后,以后每次对其进行的变更都将记录为一个差值,直到建成下一个基线。
资源
- 书籍
- 文章
- 工具
- 文档模板
- 软件工程文档标准模板百度网盘下载 - 下载密码:uu1f
一篇文章让你彻底掌握 Shell
由于 bash 是 Linux 标准默认的 shell 解释器,可以说 bash 是 shell 编程的基础。
本文主要介绍 bash 的语法,对于 linux 指令不做任何介绍。
📦 本文已归档到:『blog』
💻 本文的源码已归档到『 linux-tutorial』
1 | ███████╗██╗ ██╗███████╗██╗ ██╗ |
简介
什么是 shell
- Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。
- Shell 既是一种命令语言,又是一种程序设计语言。
- Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问 Linux 内核的服务。
Ken Thompson 的 sh 是第一种 Unix Shell,Windows Explorer 是一个典型的图形界面 Shell。
什么是 shell 脚本
Shell 脚本(shell script),是一种为 shell 编写的脚本程序,一般文件后缀为 .sh。
业界所说的 shell 通常都是指 shell 脚本,但 shell 和 shell script 是两个不同的概念。
Shell 环境
Shell 编程跟 java、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Shell 的解释器种类众多,常见的有:
- sh - 即 Bourne Shell。sh 是 Unix 标准默认的 shell。
- bash - 即 Bourne Again Shell。bash 是 Linux 标准默认的 shell。
- fish - 智能和用户友好的命令行 shell。
- xiki - 使 shell 控制台更友好,更强大。
- zsh - 功能强大的 shell 与脚本语言。
指定脚本解释器
在 shell 脚本,#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 解释器。#! 被称作shebang(也称为 Hashbang )。
所以,你应该会在 shell 中,见到诸如以下的注释:
- 指定 sh 解释器
1 | !/bin/sh |
- 指定 bash 解释器
1 | !/bin/bash |
注意
上面的指定解释器的方式是比较常见的,但有时候,你可能也会看到下面的方式:
这样做的好处是,系统会自动在
PATH环境变量中查找你指定的程序(本例中的bash)。相比第一种写法,你应该尽量用这种写法,因为程序的路径是不确定的。这样写还有一个好处,操作系统的PATH变量有可能被配置为指向程序的另一个版本。比如,安装完新版本的bash,我们可能将其路径添加到PATH中,来“隐藏”老版本。如果直接用#!/bin/bash,那么系统会选择老版本的bash来执行脚本,如果用#!/usr/bin/env bash,则会使用新版本。
模式
shell 有交互和非交互两种模式。
交互模式
简单来说,你可以将 shell 的交互模式理解为执行命令行。
看到形如下面的东西,说明 shell 处于交互模式下:
1 | user@host:~$ |
接着,便可以输入一系列 Linux 命令,比如 ls,grep,cd,mkdir,rm 等等。
非交互模式
简单来说,你可以将 shell 的非交互模式理解为执行 shell 脚本。
在非交互模式下,shell 从文件或者管道中读取命令并执行。
当 shell 解释器执行完文件中的最后一个命令,shell 进程终止,并回到父进程。
可以使用下面的命令让 shell 以非交互模式运行:
1 | sh /path/to/script.sh |
上面的例子中,script.sh是一个包含 shell 解释器可以识别并执行的命令的普通文本文件,sh和bash是 shell 解释器程序。你可以使用任何喜欢的编辑器创建script.sh(vim,nano,Sublime Text, Atom 等等)。
其中,source /path/to/script.sh 和 ./path/to/script.sh 是等价的。
除此之外,你还可以通过chmod命令给文件添加可执行的权限,来直接执行脚本文件:
1 | chmod +x /path/to/script.sh #使脚本具有执行权限 |
这种方式要求脚本文件的第一行必须指明运行该脚本的程序,比如:
💻 『示例源码』
1 | !/usr/bin/env bash |
上面的例子中,我们使用了一个很有用的命令echo来输出字符串到屏幕上。
基本语法
解释器
前面虽然两次提到了#! ,但是本着重要的事情说三遍的精神,这里再强调一遍:
在 shell 脚本,#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 解释器。#! 被称作shebang(也称为 Hashbang )。
#! 决定了脚本可以像一个独立的可执行文件一样执行,而不用在终端之前输入sh, bash, python, php等。
1 | 以下两种方式都可以指定 shell 解释器为 bash,第二种方式更好 |
注释
注释可以说明你的代码是什么作用,以及为什么这样写。
shell 语法中,注释是特殊的语句,会被 shell 解释器忽略。
- 单行注释 - 以
#开头,到行尾结束。 - 多行注释 - 以
:<<EOF开头,到EOF结束。
💻 『示例源码』
1 | -------------------------------------------- |
echo
echo 用于字符串的输出。
输出普通字符串:
1 | echo "hello, world" |
输出含变量的字符串:
1 | echo "hello, \"zp\"" |
输出含变量的字符串:
1 | name=zp |
输出含换行符的字符串:
1 | 输出含换行符的字符串 |
输出含不换行符的字符串:
1 | echo "YES" |
输出重定向至文件
1 | echo "test" > test.txt |
输出执行结果
1 | echo `pwd` |
💻 『示例源码』
1 | !/usr/bin/env bash |
printf
printf 用于格式化输出字符串。
默认,printf 不会像 echo 一样自动添加换行符,如果需要换行可以手动添加 \n。
💻 『示例源码』
1 | 单引号 |
printf 的转义符
| 序列 | 说明 |
|---|---|
\a |
警告字符,通常为 ASCII 的 BEL 字符 |
\b |
后退 |
\c |
抑制(不显示)输出结果中任何结尾的换行字符(只在%b 格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略 |
\f |
换页(formfeed) |
\n |
换行 |
\r |
回车(Carriage return) |
\t |
水平制表符 |
\v |
垂直制表符 |
\\ |
一个字面上的反斜杠字符 |
\ddd |
表示 1 到 3 位数八进制值的字符。仅在格式字符串中有效 |
\0ddd |
表示 1 到 3 位的八进制值字符 |
变量
跟许多程序设计语言一样,你可以在 bash 中创建变量。
Bash 中没有数据类型,bash 中的变量可以保存一个数字、一个字符、一个字符串等等。同时无需提前声明变量,给变量赋值会直接创建变量。
变量命名原则
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用 bash 里的关键字(可用 help 命令查看保留关键字)。
声明变量
访问变量的语法形式为:${var} 和 $var 。
变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,所以推荐加花括号。
1 | word="hello" |
只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
1 | rword="hello" |
删除变量
使用 unset 命令可以删除变量。变量被删除后不能再次使用。unset 命令不能删除只读变量。
1 | dword="hello" # 声明变量 |
变量类型
- 局部变量 - 局部变量是仅在某个脚本内部有效的变量。它们不能被其他的程序和脚本访问。
- 环境变量 - 环境变量是对当前 shell 会话内所有的程序或脚本都可见的变量。创建它们跟创建局部变量类似,但使用的是
export关键字,shell 脚本也可以定义环境变量。
常见的环境变量:
| 变量 | 描述 |
|---|---|
$HOME |
当前用户的用户目录 |
$PATH |
用分号分隔的目录列表,shell 会到这些目录中查找命令 |
$PWD |
当前工作目录 |
$RANDOM |
0 到 32767 之间的整数 |
$UID |
数值类型,当前用户的用户 ID |
$PS1 |
主要系统输入提示符 |
$PS2 |
次要系统输入提示符 |
这里 有一张更全面的 Bash 环境变量列表。
💻 『示例源码』
1 | !/usr/bin/env bash |
字符串
单引号和双引号
shell 字符串可以用单引号 '',也可以用双引号 “”,也可以不用引号。
- 单引号的特点
- 单引号里不识别变量
- 单引号里不能出现单独的单引号(使用转义符也不行),但可成对出现,作为字符串拼接使用。
- 双引号的特点
- 双引号里识别变量
- 双引号里可以出现转义字符
综上,推荐使用双引号。
拼接字符串
1 | 使用单引号拼接 |
获取字符串长度
1 | text="12345" |
截取子字符串
1 | text="12345" |
从第 3 个字符开始,截取 2 个字符
查找子字符串
1 | !/usr/bin/env bash |
查找 ll 子字符在 hello 字符串中的起始位置。
💻 『示例源码』
1 | !/usr/bin/env bash |
数组
bash 只支持一维数组。
数组下标从 0 开始,下标可以是整数或算术表达式,其值应大于或等于 0。
创建数组
1 | 创建数组的不同方式 |
访问数组元素
- 访问数组的单个元素:
1 | echo ${nums[1]} |
- 访问数组的所有元素:
1 | echo ${colors[*]} |
上面两行有很重要(也很微妙)的区别:
为了将数组中每个元素单独一行输出,我们用 printf 命令:
1 | printf "+ %s\n" ${colors[*]} |
为什么dark和blue各占了一行?尝试用引号包起来:
1 | printf "+ %s\n" "${colors[*]}" |
现在所有的元素都在一行输出 —— 这不是我们想要的!让我们试试${colors[@]}
1 | printf "+ %s\n" "${colors[@]}" |
在引号内,${colors[@]}将数组中的每个元素扩展为一个单独的参数;数组元素中的空格得以保留。
- 访问数组的部分元素:
1 | echo ${nums[@]:0:2} |
在上面的例子中,${array[@]} 扩展为整个数组,:0:2取出了数组中从 0 开始,长度为 2 的元素。
访问数组长度
1 | echo ${#nums[*]} |
向数组中添加元素
向数组中添加元素也非常简单:
1 | colors=(white "${colors[@]}" green black) |
上面的例子中,${colors[@]} 扩展为整个数组,并被置换到复合赋值语句中,接着,对数组colors的赋值覆盖了它原来的值。
从数组中删除元素
用unset命令来从数组中删除一个元素:
1 | unset nums[0] |
💻 『示例源码』
1 | !/usr/bin/env bash |
运算符
算术运算符
下表列出了常用的算术运算符,假定变量 x 为 10,变量 y 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $x + $y 结果为 30。 |
| - | 减法 | expr $x - $y 结果为 -10。 |
| * | 乘法 | expr $x * $y 结果为 200。 |
| / | 除法 | expr $y / $x 结果为 2。 |
| % | 取余 | expr $y % $x 结果为 0。 |
| = | 赋值 | x=$y 将把变量 y 的值赋给 x。 |
| == | 相等。用于比较两个数字,相同则返回 true。 | [ $x == $y ] 返回 false。 |
| != | 不相等。用于比较两个数字,不相同则返回 true。 | [ $x != $y ] 返回 true。 |
注意:条件表达式要放在方括号之间,并且要有空格,例如: [$x==$y] 是错误的,必须写成 [ $x == $y ]。
💻 『示例源码』
1 | x=10 |
关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
下表列出了常用的关系运算符,假定变量 x 为 10,变量 y 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
-eq |
检测两个数是否相等,相等返回 true。 | [ $a -eq $b ]返回 false。 |
-ne |
检测两个数是否相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
-gt |
检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
-lt |
检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
-ge |
检测左边的数是否大于等于右边的,如果是,则返回 true。 | [ $a -ge $b ] 返回 false。 |
-le |
检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ]返回 true。 |
💻 『示例源码』
1 | x=10 |
布尔运算符
下表列出了常用的布尔运算符,假定变量 x 为 10,变量 y 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
! |
非运算,表达式为 true 则返回 false,否则返回 true。 | [ ! false ] 返回 true。 |
-o |
或运算,有一个表达式为 true 则返回 true。 | [ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
-a |
与运算,两个表达式都为 true 才返回 true。 | [ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
💻 『示例源码』
1 | x=10 |
逻辑运算符
以下介绍 Shell 的逻辑运算符,假定变量 x 为 10,变量 y 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
&& |
逻辑的 AND | [[ ${x} -lt 100 && ${y} -gt 100 ]] 返回 false |
| ` | ` |
💻 『示例源码』
1 | x=10 |
字符串运算符
下表列出了常用的字符串运算符,假定变量 a 为 “abc”,变量 b 为 “efg”:
| 运算符 | 说明 | 举例 |
|---|---|---|
= |
检测两个字符串是否相等,相等返回 true。 | [ $a = $b ] 返回 false。 |
!= |
检测两个字符串是否相等,不相等返回 true。 | [ $a != $b ] 返回 true。 |
-z |
检测字符串长度是否为 0,为 0 返回 true。 | [ -z $a ] 返回 false。 |
-n |
检测字符串长度是否为 0,不为 0 返回 true。 | [ -n $a ] 返回 true。 |
str |
检测字符串是否为空,不为空返回 true。 | [ $a ] 返回 true。 |
💻 『示例源码』
1 | x="abc" |
文件测试运算符
文件测试运算符用于检测 Unix 文件的各种属性。
属性检测描述如下:
| 操作符 | 说明 | 举例 |
|---|---|---|
| -b file | 检测文件是否是块设备文件,如果是,则返回 true。 | [ -b $file ] 返回 false。 |
| -c file | 检测文件是否是字符设备文件,如果是,则返回 true。 | [ -c $file ] 返回 false。 |
| -d file | 检测文件是否是目录,如果是,则返回 true。 | [ -d $file ] 返回 false。 |
| -f file | 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 | [ -f $file ] 返回 true。 |
| -g file | 检测文件是否设置了 SGID 位,如果是,则返回 true。 | [ -g $file ] 返回 false。 |
| -k file | 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 | [ -k $file ]返回 false。 |
| -p file | 检测文件是否是有名管道,如果是,则返回 true。 | [ -p $file ] 返回 false。 |
| -u file | 检测文件是否设置了 SUID 位,如果是,则返回 true。 | [ -u $file ] 返回 false。 |
| -r file | 检测文件是否可读,如果是,则返回 true。 | [ -r $file ] 返回 true。 |
| -w file | 检测文件是否可写,如果是,则返回 true。 | [ -w $file ] 返回 true。 |
| -x file | 检测文件是否可执行,如果是,则返回 true。 | [ -x $file ] 返回 true。 |
| -s file | 检测文件是否为空(文件大小是否大于 0),不为空返回 true。 | [ -s $file ] 返回 true。 |
| -e file | 检测文件(包括目录)是否存在,如果是,则返回 true。 | [ -e $file ] 返回 true。 |
💻 『示例源码』
1 | file="/etc/hosts" |
控制语句
条件语句
跟其它程序设计语言一样,Bash 中的条件语句让我们可以决定一个操作是否被执行。结果取决于一个包在[[ ]]里的表达式。
由[[ ]](sh中是[ ])包起来的表达式被称作 检测命令 或 基元。这些表达式帮助我们检测一个条件的结果。这里可以找到有关bash 中单双中括号区别的答案。
共有两个不同的条件表达式:if和case。
if
(1)if 语句
if在使用上跟其它语言相同。如果中括号里的表达式为真,那么then和fi之间的代码会被执行。fi标志着条件代码块的结束。
1 | 写成一行 |
(2)if else 语句
同样,我们可以使用if..else语句,例如:
1 | if [[ 2 -ne 1 ]]; then |
(3)if elif else 语句
有些时候,if..else不能满足我们的要求。别忘了if..elif..else,使用起来也很方便。
💻 『示例源码』
1 | x=10 |
case
如果你需要面对很多情况,分别要采取不同的措施,那么使用case会比嵌套的if更有用。使用case来解决复杂的条件判断,看起来像下面这样:
💻 『示例源码』
1 | exec |
每种情况都是匹配了某个模式的表达式。|用来分割多个模式,)用来结束一个模式序列。第一个匹配上的模式对应的命令将会被执行。*代表任何不匹配以上给定模式的模式。命令块儿之间要用;;分隔。
循环语句
循环其实不足为奇。跟其它程序设计语言一样,bash 中的循环也是只要控制条件为真就一直迭代执行的代码块。
Bash 中有四种循环:for,while,until和select。
for循环
for与它在 C 语言中的姊妹非常像。看起来是这样:
1 | for arg in elem1 elem2 ... elemN |
在每次循环的过程中,arg依次被赋值为从elem1到elemN。这些值还可以是通配符或者大括号扩展。
当然,我们还可以把for循环写在一行,但这要求do之前要有一个分号,就像下面这样:
1 | for i in {1..5}; do echo $i; done |
还有,如果你觉得for..in..do对你来说有点奇怪,那么你也可以像 C 语言那样使用for,比如:
1 | for (( i = 0; i < 10; i++ )); do |
当我们想对一个目录下的所有文件做同样的操作时,for就很方便了。举个例子,如果我们想把所有的.bash文件移动到script文件夹中,并给它们可执行权限,我们的脚本可以这样写:
💻 『示例源码』
1 | DIR=/home/zp |
while循环
while循环检测一个条件,只要这个条件为 _真_,就执行一段命令。被检测的条件跟if..then中使用的基元并无二异。因此一个while循环看起来会是这样:
1 | while [[ condition ]] |
跟for循环一样,如果我们把do和被检测的条件写到一行,那么必须要在do之前加一个分号。
💻 『示例源码』
1 | ## 0到9之间每个数的平方 |
until循环
until循环跟while循环正好相反。它跟while一样也需要检测一个测试条件,但不同的是,只要该条件为 假 就一直执行循环:
💻 『示例源码』
1 | x=0 |
select循环
select循环帮助我们组织一个用户菜单。它的语法几乎跟for循环一致:
1 | select answer in elem1 elem2 ... elemN |
select会打印elem1..elemN以及它们的序列号到屏幕上,之后会提示用户输入。通常看到的是$?(PS3变量)。用户的选择结果会被保存到answer中。如果answer是一个在1..N之间的数字,那么语句会被执行,紧接着会进行下一次迭代 —— 如果不想这样的话我们可以使用break语句。
💻 『示例源码』
1 | !/usr/bin/env bash |
这个例子,先询问用户他想使用什么包管理器。接着,又询问了想安装什么包,最后执行安装操作。
运行这个脚本,会得到如下输出:
1 | ./my_script |
break 和 continue
如果想提前结束一个循环或跳过某次循环执行,可以使用 shell 的break和continue语句来实现。它们可以在任何循环中使用。
break语句用来提前结束当前循环。
continue语句用来跳过某次迭代。
💻 『示例源码』
1 | 查找 10 以内第一个能整除 2 和 3 的正整数 |
💻 『示例源码』
1 | 打印10以内的奇数 |
函数
bash 函数定义语法如下:
1 | [ function ] funname [()] { |
💡 说明:
- 函数定义时,
function关键字可有可无。- 函数返回值 - return 返回函数返回值,返回值类型只能为整数(0-255)。如果不加 return 语句,shell 默认将以最后一条命令的运行结果,作为函数返回值。
- 函数返回值在调用该函数后通过
$?来获得。- 所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至 shell 解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
💻 『示例源码』
1 | !/usr/bin/env bash |
执行结果:
1 | ./function-demo.sh |
位置参数
位置参数是在调用一个函数并传给它参数时创建的变量。
位置参数变量表:
| 变量 | 描述 |
|---|---|
$0 |
脚本名称 |
$1 … $9 |
第 1 个到第 9 个参数列表 |
${10} … ${N} |
第 10 个到 N 个参数列表 |
$* or $@ |
除了$0外的所有位置参数 |
$# |
不包括$0在内的位置参数的个数 |
$FUNCNAME |
函数名称(仅在函数内部有值) |
💻 『示例源码』
1 | !/usr/bin/env bash |
执行结果:
1 | ./function-demo2.sh |
执行 ./variable-demo4.sh hello world ,然后在脚本中通过 $1、$2 … 读取第 1 个参数、第 2 个参数。。。
函数处理参数
另外,还有几个特殊字符用来处理参数:
| 参数处理 | 说明 |
|---|---|
$# |
返回参数个数 |
$* |
返回所有参数 |
$$ |
脚本运行的当前进程 ID 号 |
$! |
后台运行的最后一个进程的 ID 号 |
$@ |
返回所有参数 |
$- |
返回 Shell 使用的当前选项,与 set 命令功能相同。 |
$? |
函数返回值 |
💻 『示例源码』
1 | runner() { |
Shell 扩展
扩展 发生在一行命令被分成一个个的 记号(tokens) 之后。换言之,扩展是一种执行数学运算的机制,还可以用来保存命令的执行结果,等等。
感兴趣的话可以阅读关于 shell 扩展的更多细节。
大括号扩展
大括号扩展让生成任意的字符串成为可能。它跟 文件名扩展 很类似,举个例子:
1 | echo beg{i,a,u}n ### begin began begun |
大括号扩展还可以用来创建一个可被循环迭代的区间。
1 | echo {0..5} ### 0 1 2 3 4 5 |
命令置换
命令置换允许我们对一个命令求值,并将其值置换到另一个命令或者变量赋值表达式中。当一个命令被``或$()包围时,命令置换将会执行。举个例子:
1 | now=`date +%T` |
算数扩展
在 bash 中,执行算数运算是非常方便的。算数表达式必须包在$(( ))中。算数扩展的格式为:
1 | result=$(( ((10 + 5*3) - 7) / 2 )) |
在算数表达式中,使用变量无需带上$前缀:
1 | x=4 |
单引号和双引号
单引号和双引号之间有很重要的区别。在双引号中,变量引用或者命令置换是会被展开的。在单引号中是不会的。举个例子:
1 | echo "Your home: $HOME" ### Your home: /Users/<username> |
当局部变量和环境变量包含空格时,它们在引号中的扩展要格外注意。随便举个例子,假如我们用echo来输出用户的输入:
1 | INPUT="A string with strange whitespace." |
调用第一个echo时给了它 5 个单独的参数 —— $INPUT 被分成了单独的词,echo在每个词之间打印了一个空格。第二种情况,调用echo时只给了它一个参数(整个$INPUT 的值,包括其中的空格)。
来看一个更严肃的例子:
1 | FILE="Favorite Things.txt" |
尽管这个问题可以通过把 FILE 重命名成Favorite-Things.txt来解决,但是,假如这个值来自某个环境变量,来自一个位置参数,或者来自其它命令(find, cat, 等等)呢。因此,如果输入 可能 包含空格,务必要用引号把表达式包起来。
流和重定向
Bash 有很强大的工具来处理程序之间的协同工作。使用流,我们能将一个程序的输出发送到另一个程序或文件,因此,我们能方便地记录日志或做一些其它我们想做的事。
管道给了我们创建传送带的机会,控制程序的执行成为可能。
学习如何使用这些强大的、高级的工具是非常非常重要的。
输入、输出流
Bash 接收输入,并以字符序列或 字符流 的形式产生输出。这些流能被重定向到文件或另一个流中。
有三个文件描述符:
| 代码 | 描述符 | 描述 |
|---|---|---|
0 |
stdin |
标准输入 |
1 |
stdout |
标准输出 |
2 |
stderr |
标准错误输出 |
重定向
重定向让我们可以控制一个命令的输入来自哪里,输出结果到什么地方。这些运算符在控制流的重定向时会被用到:
| Operator | Description |
|---|---|
> |
重定向输出 |
&> |
重定向输出和错误输出 |
&>> |
以附加的形式重定向输出和错误输出 |
< |
重定向输入 |
<< |
Here 文档 语法 |
<<< |
Here 字符串 |
以下是一些使用重定向的例子:
1 | ## ls的结果将会被写到list.txt中 |
/dev/null 文件
如果希望执行某个命令,但又不希望在屏幕上显示输出结果,那么可以将输出重定向到 /dev/null:
1 | command > /dev/null |
/dev/null 是一个特殊的文件,写入到它的内容都会被丢弃;如果尝试从该文件读取内容,那么什么也读不到。但是 /dev/null 文件非常有用,将命令的输出重定向到它,会起到”禁止输出”的效果。
如果希望屏蔽 stdout 和 stderr,可以这样写:
1 | command > /dev/null 2>&1 |
Debug
shell 提供了用于 debug 脚本的工具。
如果想采用 debug 模式运行某脚本,可以在其 shebang 中使用一个特殊的选项:
1 | #!/bin/bash options |
options 是一些可以改变 shell 行为的选项。下表是一些可能对你有用的选项:
| Short | Name | Description |
|---|---|---|
-f |
noglob | 禁止文件名展开(globbing) |
-i |
interactive | 让脚本以 交互 模式运行 |
-n |
noexec | 读取命令,但不执行(语法检查) |
-t |
— | 执行完第一条命令后退出 |
-v |
verbose | 在执行每条命令前,向stderr输出该命令 |
-x |
xtrace | 在执行每条命令前,向stderr输出该命令以及该命令的扩展参数 |
举个例子,如果我们在脚本中指定了-x例如:
1 | !/bin/bash -x |
这会向stdout打印出变量的值和一些其它有用的信息:
1 | ./my_script |
有时我们值需要 debug 脚本的一部分。这种情况下,使用set命令会很方便。这个命令可以启用或禁用选项。使用-启用选项,+禁用选项:
💻 『示例源码』
1 | 开启 debug |
资源
- awesome-shell - shell 资源列表
- awesome-bash - bash 资源列表
- bash-handbook
- bash-guide - bash 基本用法指南
- bash-it - 为你日常使用、开发以及维护 shell 脚本和自定义命令提供了一个可靠的框架
- dotfiles.github.io - 上面有 bash 和其它 shell 的各种 dotfiles 集合以及 shell 框架的链接
- Runoob Shell 教程
- shellcheck - 一个静态 shell 脚本分析工具,本质上是 bash/sh/zsh 的 lint。
最后,Stack Overflow 上 bash 标签下有很多你可以学习的问题,当你遇到问题时,也是一个提问的好地方。
正则表达式
📦 本文已归档到:「blog」
简介
为了理解下面章节的内容,你需要先了解一些基本概念。
- 正则表达式 - 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
- 元字符 - 元字符(metacharacters)就是正则表达式中具有特殊意义的专用字符。
- 普通字符 - 普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
基本元字符
正则表达式的元字符难以记忆,很大程度上是因为有很多为了简化表达而出现的等价字符。
而实际上最基本的元字符,并没有那么多。对于大部分的场景,基本元字符都可以搞定。
让我们从一个个实例出发,由浅入深的去体会正则的奥妙。
多选 - |
例 匹配一个确定的字符串
1 | checkMatches("abc", "abc"); |
如果要匹配一个确定的字符串,非常简单,如例 1 所示。
如果你不确定要匹配的字符串,希望有多个选择,怎么办?
答案是:使用元字符| ,它的含义是或。
例 匹配多个可选的字符串
1 | // 测试正则表达式字符:| |
输出
1 | yes matches: yes|no |
分组 - ()
如果你希望表达式由多个子表达式组成,你可以使用 ()。
例 匹配组合字符串
1 | Assert.assertTrue(checkMatches("(play|end)(ing|ed)", "ended")); |
输出
1 | ended matches: (play|end)(ing|ed) |
指定单字符有效范围 - []
前面展示了如何匹配字符串,但是很多时候你需要精确的匹配一个字符,这时可以使用[] 。
例 字符在指定范围
1 | // 测试正则表达式字符:[] |
输出
1 | b matches: [abc] |
指定单字符无效范围 - [^]
例 字符不能在指定范围
如果需要匹配一个字符的逆操作,即字符不能在指定范围,可以使用[^]。
1 | // 测试正则表达式字符:[^] |
输出
1 | b not matches: [^abc] |
限制字符数量 - {}
如果想要控制字符出现的次数,可以使用{}。
| 字符 | 描述 |
|---|---|
{n} |
n 是一个非负整数。匹配确定的 n 次。 |
{n,} |
n 是一个非负整数。至少匹配 n 次。 |
{n,m} |
m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。 |
例 限制字符出现次数
1 | // {n}: n 是一个非负整数。匹配确定的 n 次。 |
输出
1 | a not matches: ap{1} |
转义字符 - /
如果想要查找元字符本身,你需要使用转义符,使得正则引擎将其视作一个普通字符,而不是一个元字符去处理。
1 | * 的转义字符:\* |
如果是转义符\本身,你也需要使用\\ 。
指定表达式字符串的开始和结尾 - ^、$
如果希望匹配的字符串必须以特定字符串开头,可以使用^ 。
注:请特别留意,这里的^ 一定要和 [^] 中的 “^” 区分。
例 限制字符串头部
1 | Assert.assertTrue(checkMatches("^app[a-z]{0,}", "apple")); // 字符串必须以app开头 |
输出
1 | apple matches: ^app[a-z]{0,} |
如果希望匹配的字符串必须以特定字符串开头,可以使用$ 。
例 限制字符串尾部
1 | Assert.assertTrue(checkMatches("[a-z]{0,}ing$", "playing")); // 字符串必须以ing结尾 |
输出
1 | playing matches: [a-z]{0,}ing$ |
等价字符
等价字符,顾名思义,就是对于基本元字符表达的一种简化(等价字符的功能都可以通过基本元字符来实现)。
在没有掌握基本元字符之前,可以先不用理会,因为很容易把人绕晕。
等价字符的好处在于简化了基本元字符的写法。
表示某一类型字符的等价字符
下表中的等价字符都表示某一类型的字符。
| 字符 | 描述 |
|---|---|
. |
匹配除“\n”之外的任何单个字符。 |
\d |
匹配一个数字字符。等价于[0-9]。 |
\D |
匹配一个非数字字符。等价于[^0-9]。 |
\w |
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的单词字符指的是 Unicode 字符集。 |
\W |
匹配任何非单词字符。 |
\s |
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
\S |
匹配任何可见字符。等价于[ \f\n\r\t\v]。 |
案例 基本等价字符的用法
1 | // 匹配除“\n”之外的任何单个字符 |
输出
1 | ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_ matches: .{1,} |
限制字符数量的等价字符
在基本元字符章节中,已经介绍了限制字符数量的基本元字符 - {} 。
此外,还有 *、+、? 这个三个为了简化写法而出现的等价字符,我们来认识一下。
| 字符 | 描述 |
|---|---|
* |
匹配前面的子表达式零次或多次。等价于{0,}。 |
+ |
匹配前面的子表达式一次或多次。等价于{1,}。 |
? |
匹配前面的子表达式零次或一次。等价于 {0,1}。 |
案例 限制字符数量的等价字符
1 | // *: 匹配前面的子表达式零次或多次。* 等价于{0,}。 |
输出
1 | a matches: ap* |
元字符优先级顺序
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 说明 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 括号和中括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, *任何元字符、任何字符* | 定位点和序列 |
| | | 替换 |
字符具有高于替换运算符的优先级,使得“m|food”匹配“m”或“food”。若要匹配“mood”或“food”,请使用括号创建子表达式,从而产生“(m|f)ood”。
分组构造
在基本元字符章节,提到了 () 字符可以用来对表达式分组。实际上分组还有更多复杂的用法。
所谓分组构造,是用来描述正则表达式的子表达式,用于捕获字符串中的子字符串。
捕获与非捕获
下表为分组构造中的捕获和非捕获分类。
| 表达式 | 描述 | 捕获或非捕获 |
|---|---|---|
(exp) |
匹配的子表达式 | 捕获 |
(?<name>exp) |
命名的反向引用 | 捕获 |
(?:exp) |
非捕获组 | 非捕获 |
(?=exp) |
零宽度正预测先行断言 | 非捕获 |
(?!exp) |
零宽度负预测先行断言 | 非捕获 |
(?<=exp) |
零宽度正回顾后发断言 | 非捕获 |
(?<!exp) |
零宽度负回顾后发断言 | 非捕获 |
注:Java 正则引擎不支持平衡组。
反向引用
带编号的反向引用
带编号的反向引用使用以下语法:\number
其中number 是正则表达式中捕获组的序号位置。 例如,\4 匹配第四个捕获组的内容。 如果正则表达式模式中未定义number,则将发生分析错误
例 匹配重复的单词和紧随每个重复的单词的单词(不命名子表达式)
1 | // (\w+)\s\1\W(\w+) 匹配重复的单词和紧随每个重复的单词的单词 |
输出
1 | regex = (\w+)\s\1\W(\w+), content: He said that that was the the correct answer. |
说明
(\w+): 匹配一个或多个单词字符。
\s: 与空白字符匹配。
\1: 匹配第一个组,即(\w+)。
\W: 匹配包括空格和标点符号的一个非单词字符。 这样可以防止正则表达式模式匹配从第一个捕获组的单词开头的单词。
命名的反向引用
命名后向引用通过使用下面的语法进行定义:\k<name >
例 匹配重复的单词和紧随每个重复的单词的单词(命名子表达式)
1 | // (?<duplicateWord>\w+)\s\k<duplicateWord>\W(?<nextWord>\w+) 匹配重复的单词和紧随每个重复的单词的单词 |
输出
1 | regex = (?<duplicateWord>\w+)\s\k<duplicateWord>\W(?<nextWord>\w+), content: He said that that was the the correct answer. |
说明
(?
\s: 与空白字符匹配。
\k
\W: 匹配包括空格和标点符号的一个非单词字符。 这样可以防止正则表达式模式匹配从第一个捕获组的单词开头的单词。
(?
非捕获组
(?:exp) 表示当一个限定符应用到一个组,但组捕获的子字符串并非所需时,通常会使用非捕获组构造。
例 匹配以.结束的语句。
1 | // 匹配由句号终止的语句。 |
输出
1 | regex = (?:\b(?:\w+)\W*)+\., content: This is a short sentence. Never end |
零宽断言
用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。
| 表达式 | 描述 |
|---|---|
(?=exp) |
匹配 exp 前面的位置 |
(?<=exp) |
匹配 exp 后面的位置 |
(?!exp) |
匹配后面跟的不是 exp 的位置 |
(?<!exp) |
匹配前面不是 exp 的位置 |
匹配 exp 前面的位置
(?=exp) 表示输入字符串必须匹配子表达式中的正则表达式模式,尽管匹配的子字符串未包含在匹配结果中。
1 | // \b\w+(?=\sis\b) 表示要捕获is之前的单词 |
输出
1 | regex = \b\w+(?=\sis\b), content: The dog is a Malamute. |
说明
\b: 在单词边界处开始匹配。
\w+: 匹配一个或多个单词字符。
(?=\sis\b): 确定单词字符是否后接空白字符和字符串“is”,其在单词边界处结束。 如果如此,则匹配成功。
匹配 exp 后面的位置
(?<=exp) 表示子表达式不得在输入字符串当前位置左侧出现,尽管子表达式未包含在匹配结果中。零宽度正回顾后发断言不会回溯。
1 | // (?<=\b20)\d{2}\b 表示要捕获以20开头的数字的后面部分 |
输出
1 | regex = (?<=\b20)\d{2}\b, content: 2010 1999 1861 2140 2009 |
说明
\d{2}: 匹配两个十进制数字。
{?<=\b20): 如果两个十进制数字的字边界以小数位数“20”开头,则继续匹配。
\b: 在单词边界处结束匹配。
匹配后面跟的不是 exp 的位置
(?!exp) 表示输入字符串不得匹配子表达式中的正则表达式模式,尽管匹配的子字符串未包含在匹配结果中。
例 捕获未以“un”开头的单词
1 | // \b(?!un)\w+\b 表示要捕获未以“un”开头的单词 |
输出
1 | regex = \b(?!un)\w+\b, content: unite one unethical ethics use untie ultimate |
说明
\b: 在单词边界处开始匹配。
(?!un): 确定接下来的两个的字符是否为“un”。 如果没有,则可能匹配。
\w+: 匹配一个或多个单词字符。
\b: 在单词边界处结束匹配。
匹配前面不是 exp 的位置
(?<!exp) 表示子表达式不得在输入字符串当前位置的左侧出现。 但是,任何不匹配子表达式 的子字符串不包含在匹配结果中。
例 捕获任意工作日
1 | // (?<!(Saturday|Sunday) )\b\w+ \d{1,2}, \d{4}\b 表示要捕获任意工作日(即周一到周五) |
输出
1 | regex = (?<!(Saturday|Sunday) )\b\w+ \d{1,2}, \d{4}\b, content: Monday February 1, 2010 |
贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以 a 开始,以 b 结束的字符串。如果用它来搜索 aabab 的话,它会匹配整个字符串 aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。
| 表达式 | 描述 |
|---|---|
*? |
重复任意次,但尽可能少重复 |
+? |
重复 1 次或更多次,但尽可能少重复 |
?? |
重复 0 次或 1 次,但尽可能少重复 |
{n,m}? |
重复 n 到 m 次,但尽可能少重复 |
{n,}? |
重复 n 次以上,但尽可能少重复 |
例 Java 正则中贪婪与懒惰的示例
1 | // 贪婪匹配 |
输出
1 | regex = a\w*b, content: abaabaaabaaaab |
说明
本例中代码展示的是使用不同贪婪或懒惰策略去查找字符串”abaabaaabaaaab” 中匹配以”a”开头,以”b”结尾的所有子字符串。
请从输出结果中,细细体味使用不同的贪婪或懒惰策略,对于匹配子字符串有什么影响。
最实用的正则
校验中文
描述:校验字符串中只能有中文字符(不包括中文标点符号)。中文字符的 Unicode 编码范围是\u4e00 到 \u9fa5。
如有兴趣,可以参考百度百科-Unicode 。
1 | ^[\u4e00-\u9fa5]+$ |
匹配: 春眠不觉晓
不匹配:春眠不觉晓,
校验身份证号码
描述:身份证为 15 位或 18 位。15 位是第一代身份证。从 1999 年 10 月 1 日起,全国实行公民身份证号码制度,居民身份证编号由原 15 位升至 18 位。
15 位身份证
描述:由 15 位数字组成。排列顺序从左至右依次为:六位数字地区码;六位数字出生日期;三位顺序号,其中 15 位男为单数,女为双数。
18 位身份证
描述:由十七位数字本体码和一位数字校验码组成。排列顺序从左至右依次为:六位数字地区码;八位数字出生日期;三位数字顺序码和一位数字校验码(也可能是 X)。
身份证号含义详情请见:百度百科-居民身份证号码
地区码(6 位)
1 | (1[1-5]|2[1-3]|3[1-7]|4[1-3]|5[0-4]|6[1-5])\d{4} |
出生日期(8 位)
注:下面的是 18 位身份证的有效出生日期,如果是 15 位身份证,只要将第一个\d{4}改为\d{2}即可。
1 | ((\d{4}((0[13578]|1[02])(0[1-9]|[12]\d|3[01])|(0[13456789]|1[012])(0[1-9]|[12]\d|30)|02(0[1-9]|1\d|2[0-8])))|([02468][048]|[13579][26])0229) |
15 位有效身份证
1 | ^((1[1-5]|2[1-3]|3[1-7]|4[1-3]|5[0-4]|6[1-5])\d{4})((\d{2}((0[13578]|1[02])(0[1-9]|[12]\d|3[01])|(0[13456789]|1[012])(0[1-9]|[12]\d|30)|02(0[1-9]|1\d|2[0-8])))|([02468][048]|[13579][26])0229)(\d{3})$ |
匹配:110001700101031
不匹配:110001701501031
18 位有效身份证
1 | ^((1[1-5]|2[1-3]|3[1-7]|4[1-3]|5[0-4]|6[1-5])\d{4})((\d{4}((0[13578]|1[02])(0[1-9]|[12]\d|3[01])|(0[13456789]|1[012])(0[1-9]|[12]\d|30)|02(0[1-9]|1\d|2[0-8])))|([02468][048]|[13579][26])0229)(\d{3}(\d|X))$ |
匹配:110001199001010310 | 11000019900101015X
不匹配:990000199001010310 | 110001199013010310
校验有效用户名、密码
描述:长度为 6-18 个字符,允许输入字母、数字、下划线,首字符必须为字母。
1 | ^[a-zA-Z]\w{5,17}$ |
匹配:he_llo@worl.d.com | hel.l-o@wor-ld.museum | h1ello@123.com
不匹配:hello@worl_d.com | he&llo@world.co1 | .hello@wor#.co.uk
校验邮箱
描述:不允许使用 IP 作为域名,如 : hello@154.145.68.12
@符号前的邮箱用户和.符号前的域名(domain)必须满足以下条件:
- 字符只能是英文字母、数字、下划线
_、.、-; - 首字符必须为字母或数字;
_、.、-不能连续出现。
域名的根域只能为字母,且至少为两个字符。
1 | ^[A-Za-z0-9](([_\.\-]?[a-zA-Z0-9]+)*)@([A-Za-z0-9]+)(([\.\-]?[a-zA-Z0-9]+)*)\.([A-Za-z]{2,})$ |
匹配:he_llo@worl.d.com | hel.l-o@wor-ld.museum | h1ello@123.com
不匹配:hello@worl_d.com | he&llo@world.co1 | .hello@wor#.co.uk
校验 URL
描述:校验 URL。支持 http、https、ftp、ftps。
1 | ^(ht|f)(tp|tps)\://[a-zA-Z0-9\-\.]+\.([a-zA-Z]{2,3})?(/\S*)?$ |
匹配:http://google.com/help/me | http://www.google.com/help/me/ | https://www.google.com/help.asp | ftp://www.google.com | ftps://google.org
不匹配:http://un/www.google.com/index.asp
校验时间
描述:校验时间。时、分、秒必须是有效数字,如果数值不是两位数,十位需要补零。
1 | ^([0-1][0-9]|[2][0-3]):([0-5][0-9])$ |
匹配:00:00:00 | 23:59:59 | 17:06:30
不匹配:17:6:30 | 24:16:30
校验日期
描述:校验日期。日期满足以下条件:
- 格式 yyyy-MM-dd 或 yyyy-M-d
- 连字符可以没有或是“-”、“/”、“.”之一
- 闰年的二月可以有 29 日;而平年不可以。
- 一、三、五、七、八、十、十二月为 31 日。四、六、九、十一月为 30 日。
1 | ^(?:(?!0000)[0-9]{4}([-/.]?)(?:(?:0?[1-9]|1[0-2])\1(?:0?[1-9]|1[0-9]|2[0-8])|(?:0?[13-9]|1[0-2])\1(?:29|30)|(?:0?[13578]|1[02])\1(?:31))|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)([-/.]?)0?2\2(?:29))$ |
匹配:2016/1/1 | 2016/01/01 | 20160101 | 2016-01-01 | 2016.01.01 | 2000-02-29
不匹配:2001-02-29 | 2016/12/32 | 2016/6/31 | 2016/13/1 | 2016/0/1
校验中国手机号码
描述:中国手机号码正确格式:11 位数字。
移动有 16 个号段:134、135、136、137、138、139、147、150、151、152、157、158、159、182、187、188。其中 147、157、188 是 3G 号段,其他都是 2G 号段。联通有 7 种号段:130、131、132、155、156、185、186。其中 186 是 3G(WCDMA)号段,其余为 2G 号段。电信有 4 个号段:133、153、180、189。其中 189 是 3G 号段(CDMA2000),133 号段主要用作无线网卡号。总结:13 开头手机号 0-9;15 开头手机号 0-3、5-9;18 开头手机号 0、2、5-9。
此外,中国在国际上的区号为 86,所以手机号开头有+86、86 也是合法的。
以上信息来源于 百度百科-手机号
1 | ^((\+)?86\s*)?((13[0-9])|(15([0-3]|[5-9]))|(18[0,2,5-9]))\d{8}$ |
匹配:+86 18012345678 | 86 18012345678 | 15812345678
不匹配:15412345678 | 12912345678 | 180123456789
校验中国固话号码
描述:固话号码,必须加区号(以 0 开头)。
3 位有效区号:010、020~029,固话位数为 8 位。
4 位有效区号:03xx 开头到 09xx,固话位数为 7。
如果想了解更详细的信息,请参考 百度百科-电话区号 。
1 | ^(010|02[0-9])(\s|-)\d{8}|(0[3-9]\d{2})(\s|-)\d{7}$ |
匹配:010-12345678 | 010 12345678 | 0512-1234567 | 0512 1234567
不匹配:1234567 | 12345678
校验 IPv4 地址
描述:IP 地址是一个 32 位的二进制数,通常被分割为 4 个“8 位二进制数”(也就是 4 个字节)。IP 地址通常用“点分十进制”表示成(a.b.c.d)的形式,其中,a,b,c,d 都是 0~255 之间的十进制整数。
1 | ^([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])$ |
匹配:0.0.0.0 | 255.255.255.255 | 127.0.0.1
不匹配:10.10.10 | 10.10.10.256
校验 IPv6 地址
描述:IPv6 的 128 位地址通常写成 8 组,每组为四个十六进制数的形式。
IPv6 地址可以表示为以下形式:
- IPv6 地址
- 零压缩 IPv6 地址(section 2.2 of rfc5952)
- 带有本地链接区域索引的 IPv6 地址 (section 11 of rfc4007)
- 嵌入 IPv4 的 IPv6 地址(section 2 of rfc6052
- 映射 IPv4 的 IPv6 地址 (section 2.1 of rfc2765)
- 翻译 IPv4 的 IPv6 地址 (section 2.1 of rfc2765)
显然,IPv6 地址的表示方式很复杂。你也可以参考
Stack overflow 上的 IPv6 正则表达高票答案
1 | (([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])) |
匹配:1:2:3:4:5:6:7:8 | 1:: | 1::8 | 1::6:7:8 | 1::5:6:7:8 | 1::4:5:6:7:8 | 1::3:4:5:6:7:8 | ::2:3:4:5:6:7:8 | 1:2:3:4:5:6:7:: | 1:2:3:4:5:6::8 | 1:2:3:4:5::8 | 1:2:3:4::8 | 1:2:3::8 | 1:2::8 | 1::8 | ::8 | fe80::7:8%1 | ::255.255.255.255 | 2001:db8:3:4::192.0.2.33 | 64:ff9b::192.0.2.33
不匹配:1.2.3.4.5.6.7.8 | 1::2::3
特定字符
匹配长度为 3 的字符串:^.{3}$。
匹配由 26 个英文字母组成的字符串:^[A-Za-z]+$。
匹配由 26 个大写英文字母组成的字符串:^[A-Z]+$。
匹配由 26 个小写英文字母组成的字符串:^[a-z]+$。
匹配由数字和 26 个英文字母组成的字符串:^[A-Za-z0-9]+$。
匹配由数字、26 个英文字母或者下划线组成的字符串:^\w+$。
特定数字
匹配正整数:^[1-9]\d*$
匹配负整数:^-[1-9]\d*$
匹配整数:^(-?[1-9]\d*)|0$
匹配正浮点数:^[1-9]\d*\.\d+|0\.\d+$
匹配负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$
匹配浮点数:^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
速查元字符字典
为了方便快查正则的元字符含义,在本节根据元字符的功能集中罗列正则的各种元字符。
限定符
| 字符 | 描述 |
|---|---|
* |
匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
+ |
匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
? |
匹配前面的子表达式零次或一次。例如,”do(es)?” 可以匹配 “do” 或 “does” 中的”do” 。? 等价于 {0,1}。 |
{n} |
n 是一个非负整数。匹配确定的 n 次。例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
{n,} |
n 是一个非负整数。至少匹配 n 次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等价于 ‘o+’。’o{0,}’ 则等价于 ‘o*‘。 |
{n,m} |
m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 将匹配 “fooooood” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
定位符
| 字符 | 描述 |
|---|---|
^ |
匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
$ |
匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
\b |
匹配一个字边界,即字与空格间的位置。 |
\B |
非字边界匹配。 |
非打印字符
| 字符 | 描述 |
|---|---|
\cx |
匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
\f |
匹配一个换页符。等价于 \x0c 和 \cL。 |
\n |
匹配一个换行符。等价于 \x0a 和 \cJ。 |
\r |
匹配一个回车符。等价于 \x0d 和 \cM。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
\S |
匹配任何非空白字符。等价于 [ \f\n\r\t\v]。 |
\t |
匹配一个制表符。等价于 \x09 和 \cI。 |
\v |
匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
分组
| 表达式 | 描述 |
|---|---|
(exp) |
匹配的子表达式。()中的内容就是子表达式。 |
(?<name>exp) |
命名的子表达式(反向引用)。 |
(?:exp) |
非捕获组,表示当一个限定符应用到一个组,但组捕获的子字符串并非所需时,通常会使用非捕获组构造。 |
(?=exp) |
匹配 exp 前面的位置。 |
(?<=exp) |
匹配 exp 后面的位置。 |
(?!exp) |
匹配后面跟的不是 exp 的位置。 |
(?<!exp) |
匹配前面不是 exp 的位置。 |
特殊符号
| 字符 | 描述 |
|---|---|
\ |
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\‘ 匹配 “",而 ‘(‘ 则匹配 “(“。 |
| |
指明两项之间的一个选择。 |
[] |
匹配方括号范围内的任意一个字符。形式如:[xyz]、[^xyz]、[a-z]、[^a-z]、[x,y,z] |