Pipe IPC 在 Go 中的使用与实现。
缓存淘汰策略
LRU 与 LFU 缓存策略及其实现。
关于一而再再而三的TCP粘包拆包问题的大字报
TCP 所谓的粘包和拆包问题,是技术圈里最奇葩的问题之一!
一而再,再而三,就跟傻逼的中国球迷支持中国足球队一样,前赴后继。有时候同一个人多次在犯同一个错误,有时候是前脚一个犯错了后脚又来一个还犯同样的错。即使是最优秀的程序员,也会在这个问题上面栽跟头,思维甚至很难转过弯,很久才能意识到自己的错误。而低水平的程序员就更不用说了,很多人到死都没有理解这个错误并解决掉,只是逃掉了而已。
我们固然可以认为原因是某些人学艺不精,但那么多的人,其中包括无数的优秀程序员在 TCP 粘包和拆包问题在犯错误,难道我们不能说,这其实是 TCP 自身的原因吗?
在我看来,这个问题的出现,原因就在于 TCP 协议是有原罪的 – 也就是 TCP 协议所谓的“流式”协议。所以,我要炮轰 TCP!
经过几十年的验证,除了几数几个网络协议会用到 TCP 所谓的流式特性之外,没有任何应用协议使用流式特性。我们必须承认,所有的应用层协议都是基于报文的协议,而不是流式协议。而某些名字中带有”流(Stream)”字样的协议,如 RTP,流媒体等,其本质是无数小体积的报文按顺序拼接而成,根本就和 TCP 的流式没有任何关系!
那么我们就可以确定,数据的本质是报文,流数据是某类报文数据的一种伪称。事实,TCP 的流就是基于 IP 报文的。
因为“流”是一个伪抽象的概念,所以流式协议是违反人的天性和事物的内在逻辑的。万物的本质是报文。这因为如此,”流”所引出的粘包拆包问题,就必然会一而再,再而三,大量地出现。
炮轰之后,我们要怎么解决问题呢?
由于 TCP 协议已经成为事实上的基础,所以淘汰掉 TCP 是不可想象的。我们要做的是,找到正确的编程代码,解决粘包拆包问题。经过无数人的探索,以及无数人一次又一次重复的愚蠢错误的反证,我发现了解决 TCP 粘包和拆包问题只有一条路径,没有第二条!我断言,所有和我的解决方案不同的代码,都是错误的。
彻底解决 TCP 粘包和拆包问题的代码架构如下:
1 | char tmp[]; |
这段代码是终极地解决 TCP 粘包和拆包问题的代码!
这段代码之所以正确,是因为它包含了两个循环:网络循环和解析循环。
网络循环用于从 TCP socket 中读取流式数据,每一次读取到的数据的长度是不可预期,也就是,读取到的数据长短不一,无法保证,这就是所谓“流式”引出的问题。
而解析循环的功能是从拼接后流数据中,尝试解析出多个报文。注意,是多个报文,不是一个。因为所谓的粘包问题存在,所以可能是多个,而不是一个。如果解析不成功,那说明是遇到了拆包问题,我们继续读网络数据。
你只需要死记硬背上面的正确代码即可。不死记硬背也一样,最终你还是要得出和我相同的结论写出和我一样的代码。那么,何不现在就死记硬背呢?
最后,附上经典的错误代码:
1 | tcp.read(tmp, HEADER_LEN); |
这样的代码当然是错误的,这么简单代码怎么可能是对的?如果对了,TCP 还是 TCP 吗?
如果你认为本文有用,请关注这个 GitHub 项目:http://wibliss.com 让更多人一起炮打 TCP!
该项目还提供了模拟粘包和拆包的代码,你如果不信邪,可以写一个自己的 client 试试。
构建C1000K的服务器
著名的 C10K 问题提出的时候, 正是 2001 年, 到如今 C10K 已经不是问题了, 任何一个普通的程序员, 都能利用手边的语言和库, 轻松地写出 C10K 的服务器. 这既得益于软件的进步, 也得益于硬件性能的提高.
现在, 该是考虑 C1000K, 也就是百万连接的问题的时候了. 像 Twitter, weibo, Facebook 这些网站, 它们的同时在线用户有上千万, 同时又希望消息能接近实时地推送给用户, 这就需要服务器能维持和上千万用户的 TCP 网络连接, 虽然可以使用成百上千台服务器来支撑这么多用户, 但如果每台服务器能支持一百万连接(C1000K), 那么只需要十台服务器.
有很多技术声称能解决 C1000K 问题, 例如 Erlang, Java NIO 等等, 不过, 我们应该首先弄明白, 什么因素限制了 C1000K 问题的解决. 主要是这几点:
- 操作系统能否支持百万连接?
- 操作系统维持百万连接需要多少内存?
- 应用程序维持百万连接需要多少内存?
- 百万连接的吞吐量是否超过了网络限制?
下面来分别对这几个问题进行分析.
1. 操作系统能否支持百万连接?
对于绝大部分 Linux 操作系统, 默认情况下确实不支持 C1000K! 因为操作系统包含最大打开文件数(Max Open Files)限制, 分为系统全局的, 和进程级的限制.
- 全局限制
在 Linux 下执行:
1 | [root@centos ~]# cat /proc/sys/fs/file-nr |
第三个数字 184278 就是当前系统的全局最大打开文件数(Max Open Files), 可以看到, 只有 18 万, 所以, 在这台服务器上无法支持 C1000K. 很多系统的这个数值更小, 为了修改这个数值, 用 root 权限修改 /etc/sysctl.conf 文件:
1 | fs.file-max = 1020000 |
如何生效:
1 | Linux |
- 进程限制
执行:
1 | [root@centos ~]# ulimit -n |
说明当前 Linux 系统的每一个进程只能最多打开 1024 个文件. 为了支持 C1000K, 你同样需要修改这个限制.
临时修改:
1 | ulimit -n 1020000 |
不过, 如果你不是 root, 可能不能修改超过 1024, 否则会报错:
1 | [zhudp@centos ~]$ ulimit -n 1025 |
永久修改:
编辑 /etc/security/limits.conf 文件, 加入如下行:
1 | # /etc/security/limits.conf |
第一列的 root 表示 root 用户, 你可以填 *, 或者其他用户名. 然后保存退出, 重新登录服务器.
注意: Linux 内核源码中有一个常量(NR_OPEN in /usr/include/linux/fs.h), 限制了最大打开文件数, 如 RHEL 5 是 1048576(2^20), 所以, 要想支持 C1000K, 你可能还需要重新编译内核.
2. 操作系统维持百万连接需要多少内存?
3. 应用程序维持百万连接需要多少内存?
4. 百万连接的吞吐量是否超过了网络限制?
经典的客户端最多能发起65536个连接的误解
“因为 TCP 端口号是 16 位无符号整数, 最大 65535, 所以一台服务器最多支持 65536 个TCP socket连接.” - 一个非常经典的误解! 即使是有多年网络编程经验的人, 也会持有这个错误结论.
要戳破这个错误结论, 可以从理论和实践两方面来.
理论:
系统通过一个四元组来唯一标识一条 TCP 连接. 这个四元组的结构是(local_ip, local_port, remote_ip, remote_port), 对于 IPv4, 系统理论上最多可以管理 2^(32+16+32+16), 2 的 96 次方个连接.
对于一个 tcp client而言,本地 ip 是确定的,server 的 ip 和 port 也是确定的,那么客户端能够维持的 TCP 连接数量是 2^16(65536)个。如果我们在 server 上再多监听一个端口,那么理论上 client 到 server 之间就能够维持 2^16 * 2 个 TCP 连接。
实践:
TCP 客户端(TCP 的主动发起者)可以在同一 ip:port 上向不同的服务器发起主动连接, 只需在 Bind 之前对 socket 设置 SO_REUSEADDR 选项即可。
服务器端代码:
1 | func main() { |
客户端代码:
1 | var mu sync.Mutex |
是什么限制了服务器的 TCP 连接数:
- 端口范围
如果某个客户端向同一个 TCP 端点 (ip:port) 发起主动连接, 那么每一条连接都必须使用不同的本地TCP端点, 如果客户端只有一个IP则是使用不同的本地端口, 该端口的范围在 linux 系统上的一个例子是32768到61000, 可以通过如下命令查看:
1 | [root@VM_0_13_centos ~]# cat /proc/sys/net/ipv4/ip_local_port_range |
也就是说, 一个客户端连接同一个服务器的同一个ip:port(比如进行压力测试), 最多可以发起30000个左右的连接.
TCP客户端(TCP的主动发起者)可以在同一ip:port上向不同的服务器发起主动连接, 只需在bind之前对socket设置 SO_REUSEADDR 选项.
- 系统支持的最大打开文件描述符数
全局限制:
1 | [root@VM_0_13_centos ~]# cat /proc/sys/fs/file-max |
进程限制:
1 | [root@VM_0_13_centos ~]# ulimit -n |
结论:
无论是对于服务器还是客户端, 认为“一台机器最多建立65536个TCP连接”是没有根据的, 理论上远远超过这个值.
另外, 对于client端, 操作系统会自动根据不同的远端 ip:port, 决定是否重用本地端口.
构建C1000K的服务器
著名的 C10K 问题提出的时候, 正是 2001 年, 到如今 C10K 已经不是问题了, 任何一个普通的程序员, 都能利用手边的语言和库, 轻松地写出 C10K 的服务器. 这既得益于软件的进步, 也得益于硬件性能的提高.
现在, 该是考虑 C1000K, 也就是百万连接的问题的时候了. 像 Twitter, weibo, Facebook 这些网站, 它们的同时在线用户有上千万, 同时又希望消息能接近实时地推送给用户, 这就需要服务器能维持和上千万用户的 TCP 网络连接, 虽然可以使用成百上千台服务器来支撑这么多用户, 但如果每台服务器能支持一百万连接(C1000K), 那么只需要十台服务器.
经典的客户端最多能发起65536个连接的误解
“因为 TCP 端口号是 16 位无符号整数, 最大 65535, 所以一台服务器最多支持 65536 个TCP socket连接.” - 一个非常经典的误解! 即使是有多年网络编程经验的人, 也会持有这个错误结论.
要戳破这个错误结论, 可以从理论和实践两方面来.
关于一而再再而三的TCP粘包拆包问题的大字报
TCP 所谓的粘包和拆包问题,是技术圈里最奇葩的问题之一!
一而再,再而三,就跟中国球迷支持中国足球队一样,前赴后继。有时候同一个人多次在犯同一个错误,有时候是前脚一个犯错了后脚又来一个还犯同样的错。即使是最优秀的程序员,也会在这个问题上面栽跟头,思维甚至很难转过弯,很久才能意识到自己的错误。而低水平的程序员就更不用说了,很多人到死都没有理解这个错误并解决掉,只是逃掉了而已。
我们固然可以认为原因是某些人学艺不精,但那么多的人,其中包括无数的优秀程序员在 TCP 粘包和拆包问题在犯错误,难道我们不能说,这其实是 TCP 自身的原因吗?
在我看来,这个问题的出现,原因就在于 TCP 协议是有原罪的 – 也就是 TCP 协议所谓的“流式”协议。所以,我要炮轰 TCP!
网络协议之 DNS
网络通信之 CDN
📦 本文已归档到:「blog」
域名系统(英文:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和 IP 地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。DNS 使用 TCP 和 UDP 端口 53。当前,对于每一级域名长度的限制是 63 个字符,域名总长度则不能超过 253 个字符。
关键词:DNS, 域名解析
简介
什么是 DNS
DNS 是一个应用层协议。
域名系统 (DNS) 的作用是将人类可读的域名 (如,www.example.com) 转换为机器可读的 IP 地址 (如,192.0.2.44)。
什么是域名
域名是由一串用点分隔符 . 组成的互联网上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的方位。域名可以说是一个 IP 地址的代称,目的是为了便于记忆后者。例如,wikipedia.org 是一个域名,和 IP 地址 208.80.152.2 相对应。人们可以直接访问 wikipedia.org 来代替 IP 地址,然后域名系统(DNS)就会将它转化成便于机器识别的 IP 地址。这样,人们只需要记忆 wikipedia.org 这一串带有特殊含义的字符,而不需要记忆没有含义的数字。
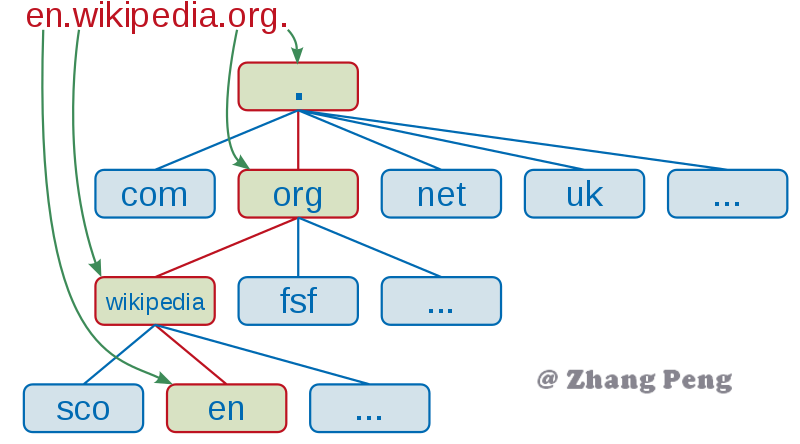
DNS 的分层
域名系统是分层次的。
在域名系统的层次结构中,各种域名都隶属于域名系统根域的下级。域名的第一级是顶级域,它包括通用顶级域,例如 .com、.net 和 .org;以及国家和地区顶级域,例如 .us、.cn 和 .tk。顶级域名下一层是二级域名,一级一级地往下。这些域名向人们提供注册服务,人们可以用它创建公开的互联网资源或运行网站。顶级域名的管理服务由对应的域名注册管理机构(域名注册局)负责,注册服务通常由域名注册商负责。
DNS 服务类型
- 授权型 DNS - 一种授权型 DNS 服务提供一种更新机制,供开发人员用于管理其公用 DNS 名称。然后,它响应 DNS 查询,将域名转换为 IP 地址,以便计算机可以相互通信。授权型 DNS 对域有最终授权且负责提供递归型 DNS 服务器对 IP 地址信息的响应。Amazon Route 53 是一种授权型 DNS 系统。
- 递归型 DNS - 客户端通常不会对授权型 DNS 服务直接进行查询。而是通常连接到称为解析程序的其他类型 DNS 服务,或递归型 DNS 服务。递归型 DNS 服务就像是旅馆的门童:尽管没有任何自身的 DNS 记录,但是可充当代表您获得 DNS 信息的中间程序。如果递归型 DNS 拥有已缓存或存储一段时间的 DNS 参考,那么它会通过提供源或 IP 信息来响应 DNS 查询。如果没有,则它会将查询传递到一个或多个授权型 DNS 服务器以查找信息。
记录类型
DNS 中,常见的资源记录类型有:
- NS 记录(域名服务) ─ 指定解析域名或子域名的 DNS 服务器。
- MX 记录(邮件交换) ─ 指定接收信息的邮件服务器。
- A 记录(地址) ─ 指定域名对应的 IPv4 地址记录。
- AAAA 记录(地址) ─ 指定域名对应的 IPv6 地址记录。
- CNAME(规范) ─ 一个域名映射到另一个域名或
CNAME记录( example.com 指向 www.example.com )或映射到一个A记录。 - PTR 记录(反向记录) ─ PTR 记录用于定义与 IP 地址相关联的名称。 PTR 记录是 A 或 AAAA 记录的逆。 PTR 记录是唯一的,因为它们以 .arpa 根开始并被委派给 IP 地址的所有者。
详细可以参考:维基百科 - 域名服务器记录类型列表
域名解析
主机名到 IP 地址的映射有两种方式:
- 静态映射 - 在本机上配置域名和 IP 的映射,旨在本机上使用。Windows 和 Linux 的 hosts 文件中的内容就属于静态映射。
- 动态映射 - 建立一套域名解析系统(DNS),只在专门的 DNS 服务器上配置主机到 IP 地址的映射,网络上需要使用主机名通信的设备,首先需要到 DNS 服务器查询主机所对应的 IP 地址。
通过域名去查询域名服务器,得到 IP 地址的过程叫做域名解析。在解析域名时,一般先静态域名解析,再动态解析域名。可以将一些常用的域名放入静态域名解析表中,这样可以大大提高域名解析效率。
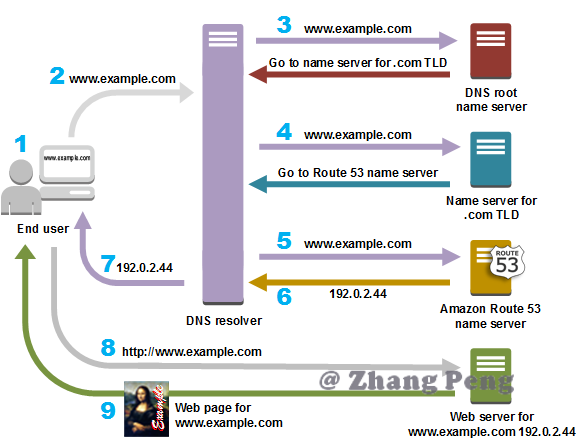
上图展示了一个动态域名解析的流程,步骤如下:
- 用户打开 Web 浏览器,在地址栏中输入 www.example.com,然后按 Enter 键。
- www.example.com 的请求被路由到 DNS 解析程序,这一般由用户的 Internet 服务提供商 (ISP) 进行管理,例如有线 Internet 服务提供商、DSL 宽带提供商或公司网络。
- ISP 的 DNS 解析程序将 www.example.com 的请求转发到 DNS 根名称服务器。
- ISP 的 DNS 解析程序再次转发 www.example.com 的请求,这次转发到 .com 域的一个 TLD 名称服务器。.com 域的名称服务器使用与 example.com 域相关的四个 Amazon Route 53 名称服务器的名称来响应该请求。
- ISP 的 DNS 解析程序选择一个 Amazon Route 53 名称服务器,并将 www.example.com 的请求转发到该名称服务器。
- Amazon Route 53 名称服务器在 example.com 托管区域中查找 www.example.com 记录,获得相关值,例如,Web 服务器的 IP 地址 (192.0.2.44),并将 IP 地址返回至 DNS 解析程序。
- ISP 的 DNS 解析程序最终获得用户需要的 IP 地址。解析程序将此值返回至 Web 浏览器。DNS 解析程序还会将 example.com 的 IP 地址缓存 (存储) 您指定的时长,以便它能够在下次有人浏览 example.com 时更快地作出响应。有关更多信息,请参阅存活期 (TTL)。
- Web 浏览器将 www.example.com 的请求发送到从 DNS 解析程序中获得的 IP 地址。这是您的内容所处位置,例如,在 Amazon EC2 实例中或配置为网站终端节点的 Amazon S3 存储桶中运行的 Web 服务器。
- 192.0.2.44 上的 Web 服务器或其他资源将 www.example.com 的 Web 页面返回到 Web 浏览器,且 Web 浏览器会显示该页面。
🔔 注意:只有配置了域名服务器,才能执行域名解析。
例如,在 Linux 中执行
vim /etc/resolv.conf命令,在其中添加下面的内容来配置域名服务器地址:
Linux 上的域名相关命令
hostname
hostname 命令用于查看和设置系统的主机名称。环境变量 HOSTNAME 也保存了当前的主机名。在使用 hostname 命令设置主机名后,系统并不会永久保存新的主机名,重新启动机器之后还是原来的主机名。如果需要永久修改主机名,需要同时修改
/etc/hosts和/etc/sysconfig/network的相关内容。
示例:
1 | $ hostname |
nslookup
nslookup 命令是常用域名查询工具,就是查 DNS 信息用的命令。
示例:
1 | [root@localhost ~]# nslookup www.jsdig.com |
更多内容
代码坏味道之代码臃肿
📦 本文已归档到:「blog」
翻译自:https://sourcemaking.com/refactoring/smells/bloaters
代码臃肿(Bloated)这组坏味道意味着:代码中的类、函数、字段没有经过合理的组织,只是简单的堆砌起来。这一类型的问题通常在代码的初期并不明显,但是随着代码规模的增长而逐渐积累(特别是当没有人努力去根除它们时)。
基本类型偏执
基本类型偏执(Primitive Obsession)
- 使用基本类型而不是小对象来实现简单任务(例如货币、范围、电话号码字符串等)。
- 使用常量编码信息(例如一个用于引用管理员权限的常量
USER_ADMIN_ROLE = 1)。- 使用字符串常量作为字段名在数组中使用。

问题原因
类似其他大部分坏味道,基本类型偏执诞生于类初建的时候。一开始,可能只是不多的字段,随着表示的特性越来越多,基本数据类型字段也越来越多。
基本类型常常被用于表示模型的类型。你有一组数字或字符串用来表示某个实体。
还有一个场景:在模拟场景,大量的字符串常量被用于数组的索引。
解决方法

大多数编程语言都支持基本数据类型和结构类型(类、结构体等)。结构类型允许程序员将基本数据类型组织起来,以代表某一事物的模型。
基本数据类型可以看成是机构类型的积木块。当基本数据类型数量成规模后,将它们有组织地结合起来,可以更方便的管理这些数据。
- 如果你有大量的基本数据类型字段,就有可能将其中部分存在逻辑联系的字段组织起来,形成一个类。更进一步的是,将与这些数据有关联的方法也一并移入类中。为了实现这个目标,可以尝试
以类取代类型码(Replace Type Code with Class)。 - 如果基本数据类型字段的值是用于方法的参数,可以使用
引入参数对象(Introduce Parameter Object)或保持对象完整(Preserve Whole Object)。 - 如果想要替换的数据值是类型码,而它并不影响行为,则可以运用
以类取代类型码(Replace Type Code with Class)将它替换掉。如果你有与类型码相关的条件表达式,可运用以子类取代类型码(Replace Type Code with Subclass)或以状态/策略模式取代类型码(Replace Type Code with State/Strategy)加以处理。 - 如果你发现自己正从数组中挑选数据,可运用
以对象取代数组(Replace Array with Object)。
收益
- 多亏了使用对象替代基本数据类型,使得代码变得更加灵活。
- 代码变得更加易读和更加有组织。特殊数据可以集中进行操作,而不像之前那样分散。不用再猜测这些陌生的常量的意义以及它们为什么在数组中。
- 更容易发现重复代码。

重构方法说明
以类取代类型码(Replace Type Code with Class)
问题
类之中有一个数值类型码,但它并不影响类的行为。
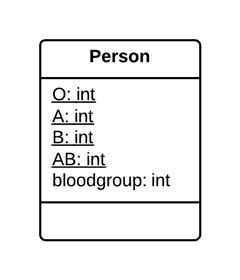
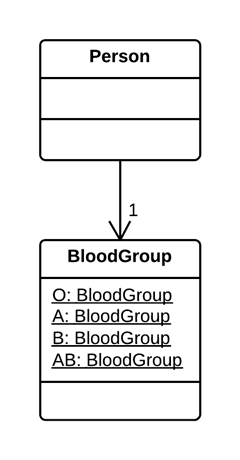
解决
以一个新的类替换该数值类型码。
引入参数对象(Introduce Parameter Object)
问题
某些参数总是很自然地同时出现。

解决
以一个对象来取代这些参数。

保持对象完整(Preserve Whole Object)
问题
你从某个对象中取出若干值,将它们作为某一次函数调用时的参数。
1 | int low = daysTempRange.getLow(); |
解决
改为传递整个对象。
1 | boolean withinPlan = plan.withinRange(daysTempRange); |
以子类取代类型码(Replace Type Code with Subclass)
问题
你有一个不可变的类型码,它会影响类的行为。

解决
以子类取代这个类型码。
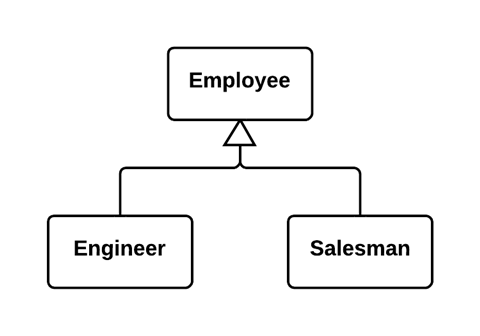
以状态/策略模式取代类型码(Replace Type Code with State/Strategy)
问题
你有一个类型码,它会影响类的行为,但你无法通过继承消除它。

解决
以状态对象取代类型码。
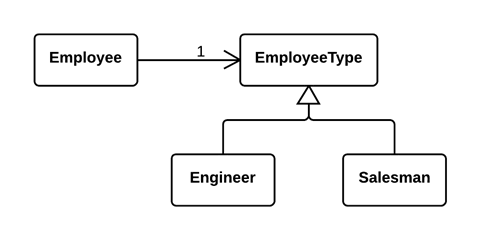
以对象取代数组(Replace Array with Object)
问题
你有一个数组,其中的元素各自代表不同的东西。
1 | String[] row = new String[3]; |
解决
以对象替换数组。对于数组中的每个元素,以一个字段来表示。
1 | Performance row = new Performance(); |
数据泥团
数据泥团(Data Clumps)
有时,代码的不同部分包含相同的变量组(例如用于连接到数据库的参数)。这些绑在一起出现的数据应该拥有自己的对象。
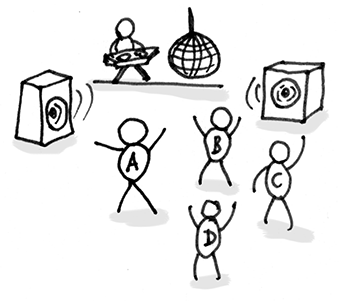
问题原因
通常,数据泥团的出现时因为糟糕的编程结构或“复制-粘贴式编程”。
有一个判断是否是数据泥团的好办法:删掉众多数据中的一项。这么做,其他数据有没有因而失去意义?如果它们不再有意义,这就是个明确的信号:你应该为它们产生一个新的对象。
解决方法
- 首先找出这些数据以字段形式出现的地方,运用
提炼类(Extract Class)将它们提炼到一个独立对象中。 - 如果数据泥团在函数的参数列中出现,运用
引入参数对象(Introduce Parameter Object)将它们组织成一个类。 - 如果数据泥团的部分数据出现在其他函数中,考虑运用
保持对象完整(Preserve Whole Object)将整个数据对象传入到函数中。 - 检视一下使用这些字段的代码,也许,将它们移入一个数据类是个不错的主意。
收益
- 提高代码易读性和组织性。对于特殊数据的操作,可以集中进行处理,而不像以前那样分散。
- 减少代码量。
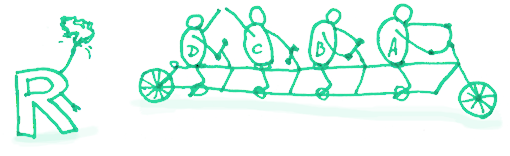
何时忽略
- 有时为了对象中的部分数据而将整个对象作为参数传递给函数,可能会产生让两个类之间不收欢迎的依赖关系,这中情况下可以不传递整个对象。
重构方法说明
提炼类(Extract Class)
问题
某个类做了不止一件事。

解决
建立一个新类,将相关的字段和函数从旧类搬移到新类。
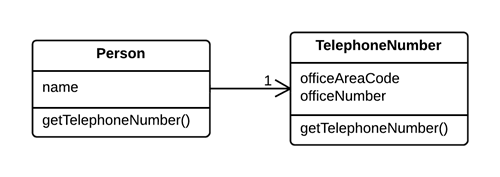
引入参数对象(Introduce Parameter Object)
问题
某些参数总是很自然地同时出现。
解决
以一个对象来取代这些参数。
保持对象完整(Preserve Whole Object)
问题
你从某个对象中取出若干值,将它们作为某一次函数调用时的参数。
1 | int low = daysTempRange.getLow(); |
解决
改为传递整个对象。
1 | boolean withinPlan = plan.withinRange(daysTempRange); |
过大的类
过大的类(Large Class)
一个类含有过多字段、函数、代码行。
问题原因
类通常一开始很小,但是随着程序的增长而逐渐膨胀。
类似于过长函数,程序员通常觉得在一个现存类中添加新特性比创建一个新的类要容易。
解决方法
设计模式中有一条重要原则:职责单一原则。一个类应该只赋予它一个职责。如果它所承担的职责太多,就该考虑为它减减负。

- 如果过大类中的部分行为可以提炼到一个独立的组件中,可以使用
提炼类(Extract Class)。 - 如果过大类中的部分行为可以用不同方式实现或使用于特殊场景,可以使用
提炼子类(Extract Subclass)。 - 如果有必要为客户端提供一组操作和行为,可以使用
提炼接口(Extract Interface)。 - 如果你的过大类是个 GUI 类,可能需要把数据和行为移到一个独立的领域对象去。你可能需要两边各保留一些重复数据,并保持两边同步。
复制被监视数据(Duplicate Observed Data)可以告诉你怎么做。
收益
- 重构过大的类可以使程序员不必记住一个类中大量的属性。
- 在大多数情况下,分割过大的类可以避免代码和功能的重复。
重构方法说明
提炼类(Extract Class)
问题
某个类做了不止一件事。
解决
建立一个新类,将相关的字段和函数从旧类搬移到新类。
提炼子类(Extract Subclass)
问题
一个类中有些特性仅用于特定场景。

解决
创建一个子类,并将用于特殊场景的特性置入其中。
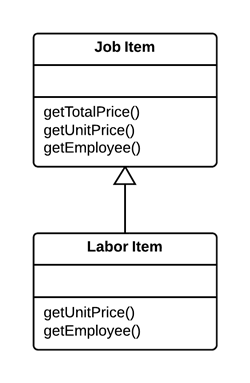
提炼接口(Extract Interface)
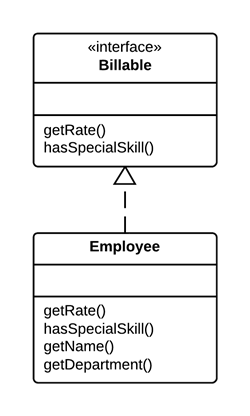
问题
多个客户端使用一个类部分相同的函数。另一个场景是两个类中的部分函数相同。
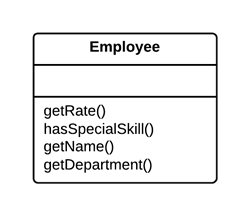
解决
移动相同的部分函数到接口中。
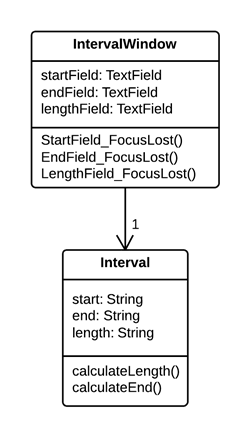
复制被监视数据(Duplicate Observed Data)
问题
如果存储在类中的数据是负责 GUI 的。

解决
一个比较好的方法是将负责 GUI 的数据放入一个独立的类,以确保 GUI 数据与域类之间的连接和同步。
过长函数
过长函数(Long Method)
一个函数含有太多行代码。一般来说,任何函数超过 10 行时,你就可以考虑是不是过长了。
函数中的代码行数原则上不要超过 100 行。
问题的原因
通常情况下,创建一个新函数的难度要大于添加功能到一个已存在的函数。大部分人都觉得:“我就添加这么两行代码,为此新建一个函数实在是小题大做了。”于是,张三加两行,李四加两行,王五加两行。。。函数日益庞大,最终烂的像一锅浆糊,再也没人能完全看懂了。于是大家就更不敢轻易动这个函数了,只能恶性循环的往其中添加代码。所以,如果你看到一个超过 200 行的函数,通常都是多个程序员东拼西凑出来的。
解决函数
一个很好的技巧是:寻找注释。添加注释,一般有这么几个原因:代码逻辑较为晦涩或复杂;这段代码功能相对独立;特殊处理。
如果代码前方有一行注释,就是在提醒你:可以将这段代码替换成一个函数,而且可以在注释的基础上给这个函数命名。如果函数有一个描述恰当的名字,就不需要去看内部代码究竟是如何实现的。就算只有一行代码,如果它需要以注释来说明,那也值得将它提炼到独立函数中。

- 为了给一个函数瘦身,可以使用
提炼函数(Extract Method)。 - 如果局部变量和参数干扰提炼函数,可以使用
以查询取代临时变量(Replace Temp with Query),引入参数对象(Introduce Parameter Object)或保持对象完整(Preserve Whole Object)。 - 如果前面两条没有帮助,可以通过
以函数对象取代函数(Replace Method with Method Object)尝试移动整个函数到一个独立的对象中。 - 条件表达式和循环常常也是提炼的信号。对于条件表达式,可以使用
分解条件表达式(Decompose Conditional)。至于循环,应该使用提炼函数(Extract Method)将循环和其内的代码提炼到独立函数中。
收益
- 在所有类型的面向对象代码中,函数比较短小精悍的类往往生命周期较长。一个函数越长,就越不容易理解和维护。
- 此外,过长函数中往往含有难以发现的重复代码。

性能
是否像许多人说的那样,增加函数的数量会影响性能?在几乎绝大多数情况下,这种影响是可以忽略不计,所以不用担心。
此外,现在有了清晰和易读的代码,在需要的时候,你将更容易找到真正有效的函数来重组代码和提高性能。
重构方法说明
提炼函数(Extract Method)
问题
你有一段代码可以组织在一起。
1 | void printOwing() { |
解决
移动这段代码到一个新的函数中,使用函数的调用来替代老代码。
1 | void printOwing() { |
以查询取代临时变量(Replace Temp with Query)
问题
将表达式的结果放在局部变量中,然后在代码中使用。
1 | double calculateTotal() { |
解决
将整个表达式移动到一个独立的函数中并返回结果。使用查询函数来替代使用变量。如果需要,可以在其他函数中合并新函数。
1 | double calculateTotal() { |
引入参数对象(Introduce Parameter Object)
问题
某些参数总是很自然地同时出现。
解决
以一个对象来取代这些参数。
保持对象完整(Preserve Whole Object)
问题
你从某个对象中取出若干值,将它们作为某一次函数调用时的参数。
1 | int low = daysTempRange.getLow(); |
解决
改为传递整个对象。
1 | boolean withinPlan = plan.withinRange(daysTempRange); |
以函数对象取代函数(Replace Method with Method Object)
问题
你有一个过长函数,它的局部变量交织在一起,以致于你无法应用提炼函数(Extract Method) 。
1 | class Order { |
解决
将函数移到一个独立的类中,使得局部变量成了这个类的字段。然后,你可以将函数分割成这个类中的多个函数。
1 | class Order { |
分解条件表达式(Decompose Conditional)
问题
你有复杂的条件表达式。
1 | if (date.before(SUMMER_START) || date.after(SUMMER_END)) { |
解决
根据条件分支将整个条件表达式分解成几个函数。
1 | if (notSummer(date)) { |
过长参数列
过长参数列(Long Parameter List)
一个函数有超过 3、4 个入参。

问题原因
过长参数列可能是将多个算法并到一个函数中时发生的。函数中的入参可以用来控制最终选用哪个算法去执行。
过长参数列也可能是解耦类之间依赖关系时的副产品。例如,用于创建函数中所需的特定对象的代码已从函数移动到调用函数的代码处,但创建的对象是作为参数传递到函数中。因此,原始类不再知道对象之间的关系,并且依赖性也已经减少。但是如果创建的这些对象,每一个都将需要它自己的参数,这意味着过长参数列。
太长的参数列难以理解,太多参数会造成前后不一致、不易使用,而且一旦需要更多数据,就不得不修改它。
解决方案
- 如果向已有的对象发出一条请求就可以取代一个参数,那么你应该使用
以函数取代参数(Replace Parameter with Methods)。在这里,,“已有的对象”可能是函数所属类里的一个字段,也可能是另一个参数。 - 你还可以运用
保持对象完整(Preserve Whole Object)将来自同一对象的一堆数据收集起来,并以该对象替换它们。 - 如果某些数据缺乏合理的对象归属,可使用
引入参数对象(Introduce Parameter Object)为它们制造出一个“参数对象”。
收益
- 更易读,更简短的代码。
- 重构可能会暴露出之前未注意到的重复代码。
何时忽略
- 这里有一个重要的例外:有时候你明显不想造成”被调用对象”与”较大对象”间的某种依赖关系。这时候将数据从对象中拆解出来单独作为参数,也很合情理。但是请注意其所引发的代价。如果参数列太长或变化太频繁,就需要重新考虑自己的依赖结构了。
重构方法说明
以函数取代参数(Replace Parameter with Methods)
问题
对象调用某个函数,并将所得结果作为参数,传递给另一个函数。而接受该参数的函数本身也能够调用前一个函数。
1 | int basePrice = quantity * itemPrice; |
解决
让参数接受者去除该项参数,并直接调用前一个函数。
1 | int basePrice = quantity * itemPrice; |
保持对象完整(Preserve Whole Object)
问题
你从某个对象中取出若干值,将它们作为某一次函数调用时的参数。
1 | int low = daysTempRange.getLow(); |
解决
改为传递整个对象。
1 | boolean withinPlan = plan.withinRange(daysTempRange); |
引入参数对象(Introduce Parameter Object)
问题
某些参数总是很自然地同时出现。
解决
以一个对象来取代这些参数。
扩展阅读
参考资料
- 重构——改善既有代码的设计 - by Martin Fowler
- https://sourcemaking.com/refactoring