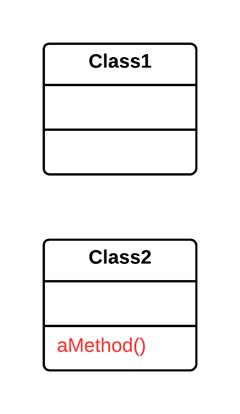
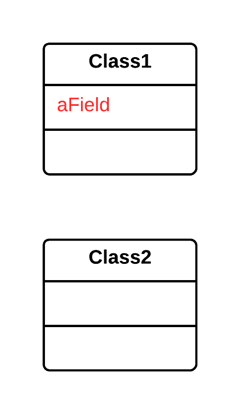
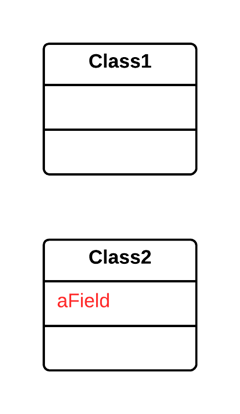
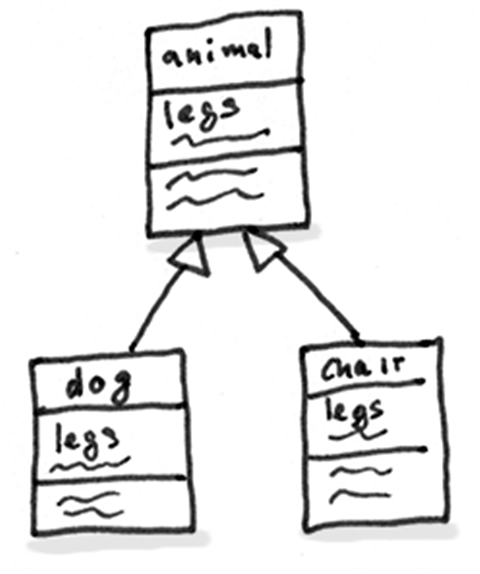
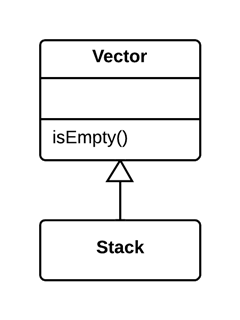
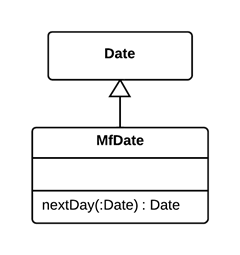
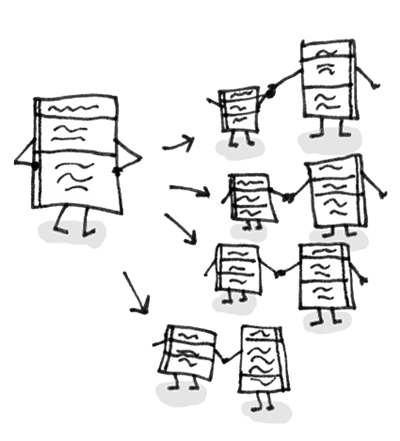
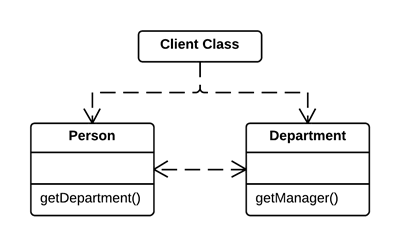
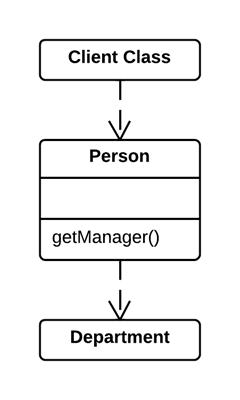
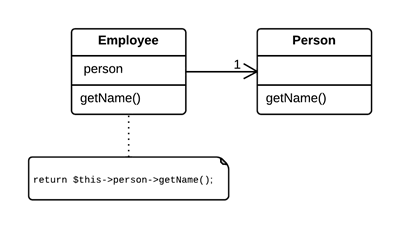
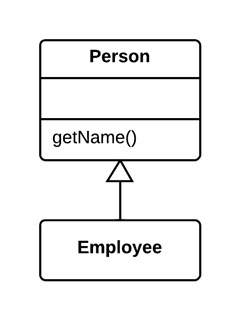
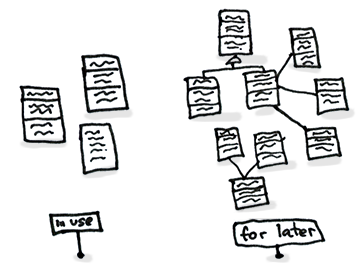
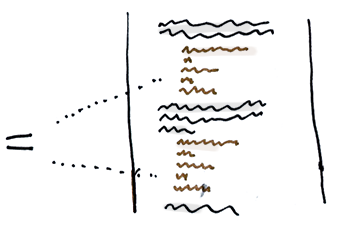
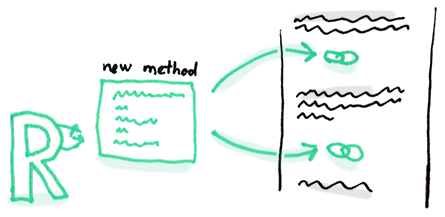
As a basic rule, if things change at the same time, you should keep them in the same place. Usually data and functions that use this data are changed together (although exceptions are possible).
doublegetExpenseLimit() { // should have either expense limit or a primary project return (expenseLimit != NULL_EXPENSE) ? expenseLimit: primaryProject.getMemberExpenseLimit(); }
String foundPerson(String[] people){ for (inti=0; i < people.length; i++) { if (people[i].equals("Don")){ return"Don"; } if (people[i].equals("John")){ return"John"; } if (people[i].equals("Kent")){ return"Kent"; } } return""; }
解决
将函数本体替换为另一个算法。
1 2 3 4 5 6 7 8 9 10
String foundPerson(String[] people){ Listcandidates= Arrays.asList(newString[] {"Don", "John", "Kent"}); for (int i=0; i < people.length; i++) { if (candidates.contains(people[i])) { return people[i]; } } return""; }
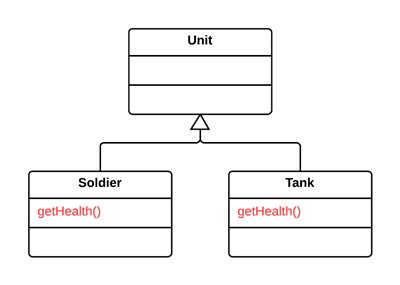
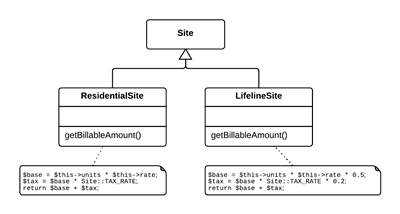
提炼超类(Extract Superclass)
问题
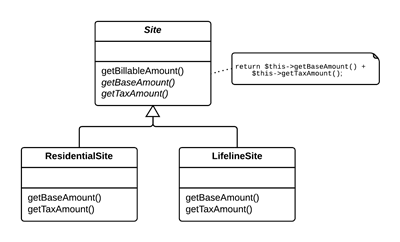
两个类有相似特性。
解决
为这两个类建立一个超类,将相同特性移至超类。
提炼类(Extract Class)
问题
某个类做了不止一件事。
解决
建立一个新类,将相关的字段和函数从旧类搬移到新类。
合并条件表达式(Consolidate Conditional Expression)
问题
你有一系列条件分支,都得到相同结果。
1 2 3 4 5 6 7 8 9 10 11 12 13
doubledisabilityAmount() { if (seniority < 2) { return0; } if (monthsDisabled > 12) { return0; } if (isPartTime) { return0; } // compute the disability amount //... }
解决
将这些条件分支合并为一个条件,并将这个条件提炼为一个独立函数。
1 2 3 4 5 6 7
doubledisabilityAmount() { if (isNotEligableForDisability()) { return0; } // compute the disability amount //... }