提升 MYSQL 查询性能最好的方法就是针对查询语句创建合适的索引。
Configuring Promtail Pipelines
A detailed look at how to setup Promtail to process your log lines, including
extracting metrics and labels.
Configuring Promtail
Promtail is configured in a YAML file (usually referred to as config.yaml)
which contains information on the Promtail server, where positions are stored,
and how to scrape logs from files.
免费软件
效率提升方法论
Travis CI 入门教程
Travis CI 入门教程
一、简介
Travis CI 提供的是持续集成服务(Continuous Integration,简称 CI)。我们在软件开发过程中,有构建、测试、部署这些必不可少的步骤,而这些会花掉我们很多的时间。为了提高软件开发的效率,现在涌现了很多自动化工具。Travis CI 是目前市场份额最大的一个,而且有很详细的文档以及可以和 Github 很好的对接。
Travis CI 是 Github 项目最流行的持续集成工具。
持续集成
持续集成(Continuous integration,缩写 CI)是一种软件工程流程,即团队开发成员经常集成他们的工作,通常每个成员每天至少集成一次,也就意味着每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽早地发现集成错误。
二、使用
加载 Github 项目
首先打开官方网站 travis-ci.org,然后使用 Github 账号登入 Travis CI,然后 Travis 中会列出你 Github 上面所有的仓库,以及你所属于的组织。
然后,勾选你需要 Travis 帮你自动构建的仓库,打开仓库旁边的开关,打开以后,Travis 就会监听这个仓库的所有变化了。
配置 .travis.yml
Travis 要求项目的根目录下面,必须有一个 .travis.yml 文件。这是配置文件,指定了 Travis 的行为。该文件必须保存在 Github 仓库里面,一旦代码仓库有新的 Commit,Travis 就会去找这个文件,执行里面的命令。
所以呢,我们就可以在这个文件里,配置我们任务(Travis 监测到仓库有 commit 后会自动执行)。
一个简单的 .travis.yml 文件如下:
1 | language: node_jsscript: true |
所以呢,我在 .travis.yml 里,配置了一个执行脚本的任务;那么现在 Travis 监测到我仓库有 commit 后就会找到 .travis.yml 这个文件,然后就执行了我的那个脚本了。
install 字段
install 字段用来指定安装脚本,如果有多个脚本,可以写成下面的形式。
1 | install: - command1 - command2 |
上面代码中,如果 command1 失败了,整个构建就会停下来,不再往下进行
如果不需要安装,即跳过安装阶段,就直接设为 true。
1 | install: true |
script 字段
script 字段用来配置构建或者测试脚本,如果有多个脚本,可以写成下面的形式。
1 | script: - command1 - command2 |
注意,script 与 install 不一样,如果 command1 失败,command2 会继续执行。但是,整个构建阶段的状态是失败。
如果 command2 只有在 command1 成功后才能执行,就要写成下面这样。
1 | script: command1 && command2 |
三、构建
四、部署
现在脚本是由 Travis CI 来执行的,部署的时候,怎么让 Travis 有权限往 Github 提交代码呢?
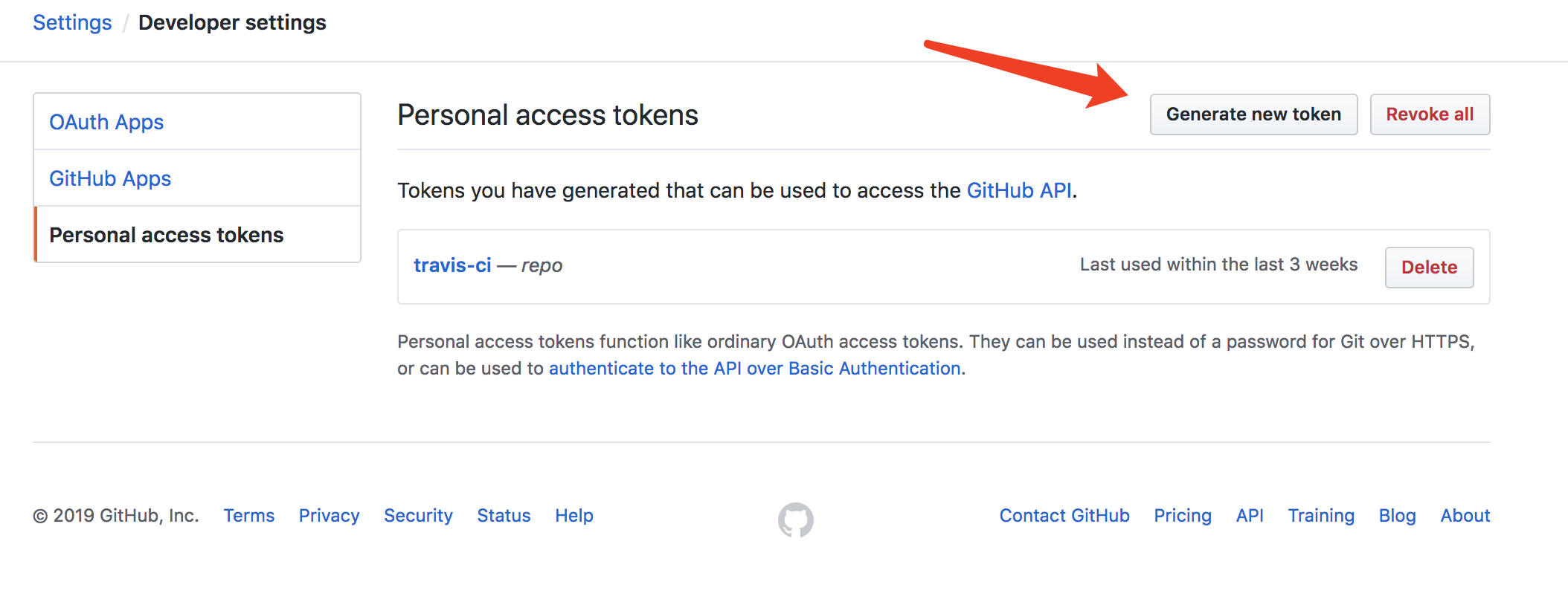
Github 有提供一个 Personal access tokens,这个 Token 与 账号密码 以及 SSH Keys 同样具有 Github 写入能力。
前往 Github 帐号 Settings 页面,在左侧选择 Personal Access Token,然后在右侧面板点击 “Generate new token” 来新建一个 Token。需要注意的是,创建完的 Token 只有第一次可见,之后再访问就无法看见(只能看见他的名称),因此要保存好这个值。
那么,这个 Token 怎么使用呢。
方案一、
一个比较方便快捷的方式,是通过 Travis 网站,写在每个仓库的设置页面里,有一个 Environment Variables 的配置项,给我们的 Token 起一个名字 gh_token 添加进去。这样以来,脚本内部就可以使用这个环境变量了。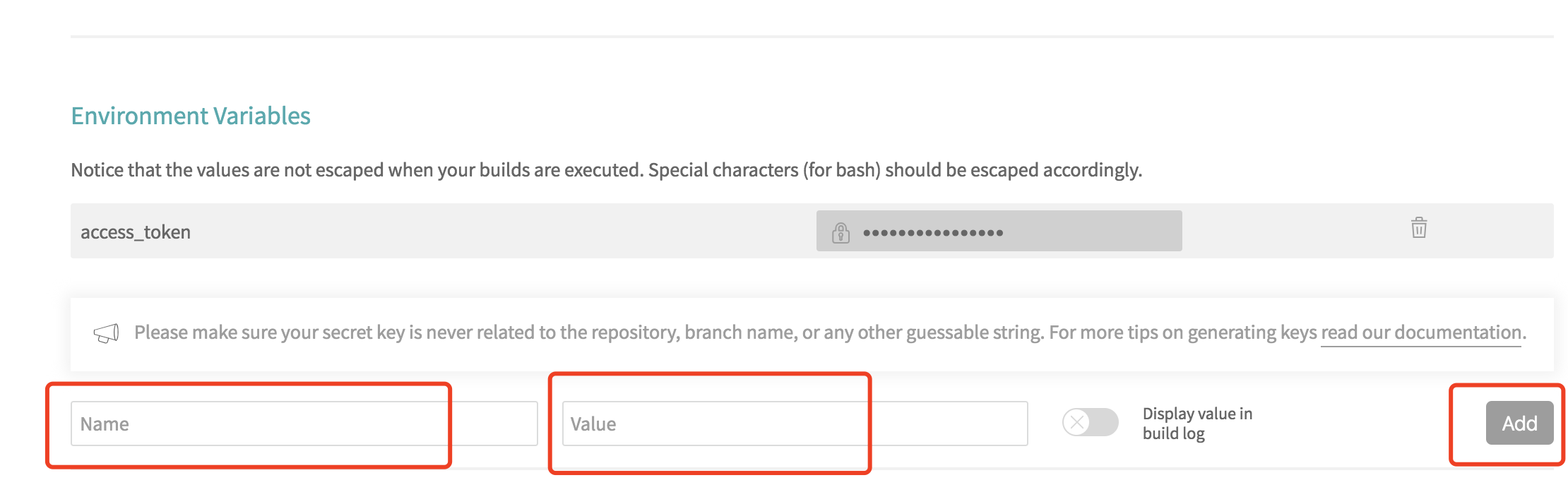
你可以在你脚本内部使用 ${gh_token} 的形式来使用这个 Token 了。【当然了,你还可以添加其他的环境变量进去。】【官方文档在这里】
使用 Personal access tokens 向 GitHub 提交代码的命令格式如下:
1 | # ${GH_TOKEN} 对应就是 Personal access tokens , GH_TOKEN 是环境变量名# ${GH_REF} 对应的是你的 Github 仓库地址,GH_REF 是变量名git push -f "https://${GH_TOKEN}@${GH_REF}" master:gh-pages |
这里需要注意的是:
1、GitHub 生成的这个 Token ,只有生成的时候可以看到明文,后面就看不到明文了,所以你使用的时候最好一次操作成功。
2、Travis CI 中添加 Token 时,记得用密文,要不然在 build log 中是可以被看到的。
方案二、
你还可以使用 Travis CI 提供的加密工具来加密我们的这个 Token。加密原理机制如下:
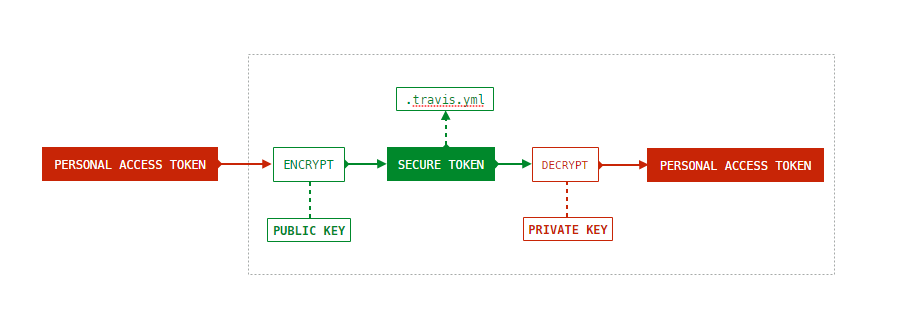
首先,安装 Ruby 的包 travis 。
1 | # 安装 Travis CI 命令行工具$ gem install travis |
然后,就可以用 travis encrypt 命令加密信息。
在项目的根目录下,执行下面的命令。
1 | $ travis encrypt name=secretvalue |
上面命令中,gh_token 是要加密的变量名,secretvalue 是要加密的变量值。执行以后,屏幕上会输出如下信息。
1 | secure: "... encrypted data ..." |
现在,就可以把这一行加入 .travis.yml 。
1 | env: global: - GH_REF: github.com/Neveryu/xxxxx.git - secure: "... entrypted data ..." |
然后,脚本里面就可以使用环境变量 gh_token 了,Travis 会在运行时自动对它解密。
1 | # ${gh_token} 对应就是 Personal access tokens , gh_token 是环境变量名# ${GH_REF} 对应的是你的 Github 仓库地址,GH_REF 是变量名git push -f "https://${gh_token}@${GH_REF}" master:gh-pages |
travis encrypt 命令的 --add 参数会把输出自动写入 .travis.yml,省掉了修改 env 字段的步骤。
1 | $ travis encrypt name=secretvalue --add |
详细信息请看官方文档
可以参考我的 vue-cms 这个项目中的 .travis.yml 文件
FAQ
如何显示 Status Image

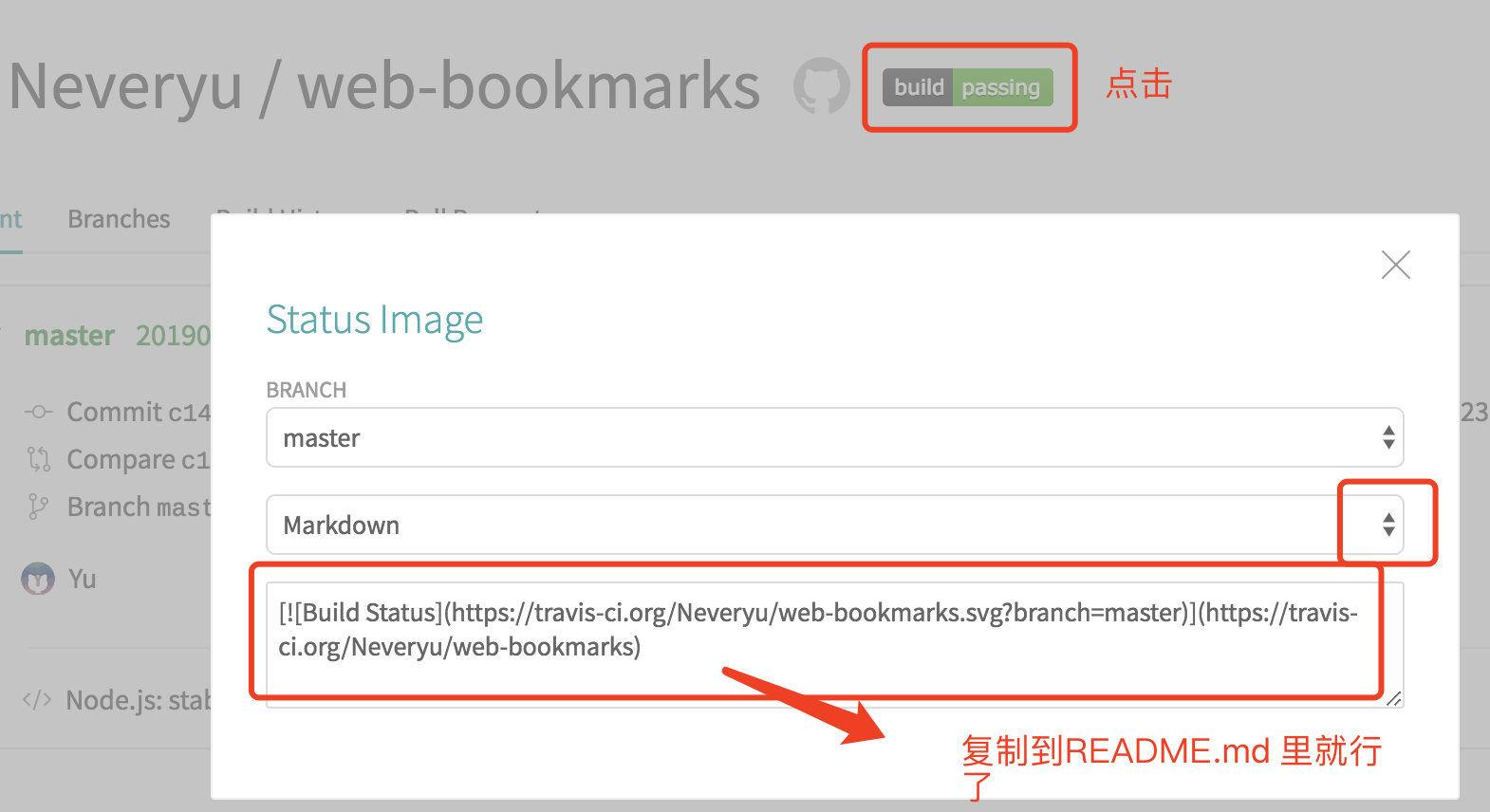
如何跳过自动构建
如果 commit 不想让 Travis 构建,那么就在 commit message 里加上 [ci skip] 就行了。
1 | git commit -m "[ci skip] commit message" |
权限问题
如果遇到脚本权限不够的提示或者问题,你可以给你的脚本加上权限:
1 | chmod u+x deploy.sh |
或者在 .travis.yml 里加:
1 | before_install: - chmod u+x deploy.sh |
参考资料
RPC 基本原理
RPC 基本原理
📦 本文已归档到:「blog」
1. 缓存概述
1.1. 什么是缓存
缓存就是数据交换的缓冲区。
缓存是用于存储数据的硬件或软件的组成部分,以使得后续更快访问相应的数据。缓存中的数据可能是提前计算好的结果、数据的副本等。典型的应用场景:有 cpu cache, 磁盘 cache 等。本文中提及到缓存主要是指互联网应用中所使用的缓存组件。
1.2. 为什么引入缓存
传统的后端业务场景中,访问量以及对响应时间的要求均不高,通常只使用数据库即可满足要求。这种架构简单,便于快速部署,很多网站发展初期均考虑使用这种架构。但是随着访问量的上升,以及对响应时间的要求提升,一个数据库服务已无法再满足要求。这时候通常会考虑数据库拆分(sharding)、读写分离、甚至硬件升级(SSD)等以满足新的业务需求。但是这种方式仍然会面临很多问题,主要体现在:
- 性能提升有限,很难达到数量级上的提升,尤其在互联网业务场景下,随着网站的发展,访问量经常会面临十倍、百倍的上涨。
- 成本高昂,为了承载 N 倍的访问量,通常需要 N 倍的机器,这个代价难以接受。
在数据层引入缓存,有以下几个好处:
- 提升数据读取速度。
- 提升系统扩展能力,通过扩展缓存,提升系统承载能力。
- 降低存储成本,Cache+DB 的方式可以承担原有需要多台 DB 才能承担的请求量,节省机器成本。
根据业务场景,通常缓存有以下几种使用方式:
- 懒汉式(读时触发):写入 DB 后, 然后把相关的数据也写入 Cache。
- 饥饿式(写时触发):先查询 DB 里的数据, 然后把相关的数据写入 Cache。
- 定期刷新:适合周期性的跑数据的任务,或者列表型的数据,而且不要求绝对实时性。
1.3. 缓存的基本原理
- 将数据写入/读取速度更快的存储(设备);
- 将数据缓存到离应用最近的位置;
- 将数据缓存到离用户最近的位置。
1.4. 缓存淘汰算法
常见的缓存淘汰算法有以下几种:
- FIFO - 先进先出,在这种淘汰算法中,先进入缓存的会先被淘汰。这种可谓是最简单的了,但是会导致我们命中率很低。试想一下我们如果有个访问频率很高的数据是所有数据第一个访问的,而那些不是很高的是后面再访问的,那这样就会把我们的首个数据但是他的访问频率很高给挤出。
- LRU - 最近最少使用算法。在这种算法中避免了上面的问题,每次访问数据都会将其放在我们的队尾,如果需要淘汰数据,就只需要淘汰队首即可。但是这个依然有个问题,如果有个数据在 1 个小时的前 59 分钟访问了 1 万次(可见这是个热点数据),再后一分钟没有访问这个数据,但是有其他的数据访问,就导致了我们这个热点数据被淘汰。
- LFU - 最近最少频率使用。在这种算法中又对上面进行了优化,利用额外的空间记录每个数据的使用频率,然后选出频率最低进行淘汰。这样就避免了 LRU 不能处理时间段的问题。
这三种缓存淘汰算法,实现复杂度一个比一个高,同样的命中率也是一个比一个好。而我们一般来说选择的方案居中即可,即实现成本不是太高,而命中率也还行的 LRU。
1.5. 缓存的分类
在分布式系统中,缓存的应用非常广泛,从部署角度有以下几个方面的缓存应用。
- CDN 缓存 - 存放 HTML、CSS、JS 等静态资源。
- 反向代理缓存 - 动静分离,只缓存用户请求的静态资源。
- 进程内缓存 - 缓存应用字典等常用数据。
- 分布式缓存 - 缓存数据库中的热点数据。
1.6. 缓存整体架构
通常,网站的缓存整体架构如下图所示:

- 浏览器向客户端发起请求,如果 CDN 有缓存则直接返回;
- 如果 CDN 无缓存,则访问反向代理服务器;
- 如果反向代理服务器有缓存则直接返回;
- 如果反向代理服务器无缓存或动态请求,则访问应用服务器;
- 应用服务器访问进程内缓存;如果有缓存,则返回代理服务器,并缓存数据;(动态请求不缓存)
- 如果进程内缓存无数据,则读取分布式缓存;并返回应用服务器;应用服务器将数据缓存到本地缓存(部分);
- 如果分布式缓存无数据,则应用程序读取数据库数据,并放入分布式缓存;
2. CDN 缓存
CDN 将数据缓存到离用户物理距离最近的服务器,使得用户可以就近获取请求内容。CDN 一般缓存静态资源文件(页面,脚本,图片,视频,文件等)。
国内网络异常复杂,跨运营商的网络访问会很慢。为了解决跨运营商或各地用户访问问题,可以在重要的城市,部署 CDN 应用。使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
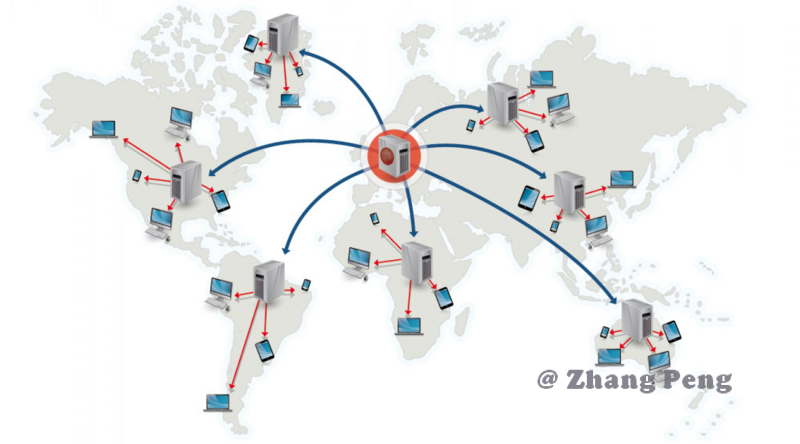
CDN 的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问网站时,利用全局负载技术将用户的访问指向距离最近的工作正常的缓存服务器上,由缓存服务器直接响应用户请求。
(1)未部署 CDN 应用前的网络路径:
- 请求:本机网络(局域网)=> 运营商网络 => 应用服务器机房
- 响应:应用服务器机房 => 运营商网络 => 本机网络(局域网)
在不考虑复杂网络的情况下,从请求到响应需要经过 3 个节点,6 个步骤完成一次用户访问操作。
(2)部署 CDN 应用后网络路径:
- 请求:本机网络(局域网) => 运营商网络
- 响应:运营商网络 => 本机网络(局域网)
在不考虑复杂网络的情况下,从请求到响应需要经过 2 个节点,2 个步骤完成一次用户访问操作。
与不部署 CDN 服务相比,减少了 1 个节点,4 个步骤的访问。极大的提高的系统的响应速度。
2.2. CDN 特点
- 优点
- 本地 Cache 加速 - 提升访问速度,尤其含有大量图片和静态页面站点;
- 镜像服务 - 消除了不同运营商之间互联的瓶颈造成的影响,实现了跨运营商的网络加速,保证不同网络中的用户都能得到良好的访问质量;
- 远程加速 - 远程访问用户根据 DNS 负载均衡技术智能自动选择 Cache 服务器,选择最快的 Cache 服务器,加快远程访问的速度;
- 带宽优化 - 自动生成服务器的远程 Mirror(镜像)cache 服务器,远程用户访问时从 cache 服务器上读取数据,减少远程访问的带宽、分担网络流量、减轻原站点 WEB 服务器负载等功能。
- 集群抗攻击 - 广泛分布的 CDN 节点加上节点之间的智能冗余机制,可以有效地预防黑客入侵以及降低各种 D.D.o.S 攻击对网站的影响,同时保证较好的服务质量。
- 缺点
- 不适宜缓存动态资源
- 解决方案:主要缓存静态资源,动态资源建立多级缓存或准实时同步;
- 存在数据的一致性问题
- 解决方案(主要是在性能和数据一致性二者间寻找一个平衡)
- 设置缓存失效时间(1 个小时,过期后同步数据)。
- 针对资源设置版本号。
- 解决方案(主要是在性能和数据一致性二者间寻找一个平衡)
- 不适宜缓存动态资源
3. 反向代理缓存
反向代理(Reverse Proxy)方式是指以代理服务器来接受 internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 internet 上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
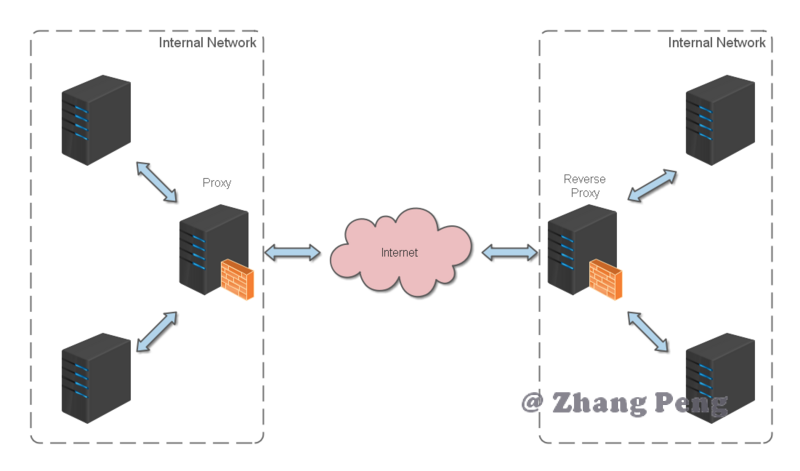
反向代理位于应用服务器同一网络,处理所有对 WEB 服务器的请求。
反向代理缓存的原理:
- 如果用户请求的页面在代理服务器上有缓存的话,代理服务器直接将缓存内容发送给用户。
- 如果没有缓存则先向 WEB 服务器发出请求,取回数据,本地缓存后再发送给用户。
这种方式通过降低向 WEB 服务器的请求数,从而降低了 WEB 服务器的负载。
反向代理缓存一般针对的是静态资源,而将动态资源请求转发到应用服务器处理。常用的缓存应用服务器有 Varnish,Ngnix,Squid。
3.2. 代理缓存比较
常用的代理缓存有 Varnish,Squid,Ngnix,简单比较如下:
- Varnish 和 Squid 是专业的 cache 服务,Ngnix 需要第三方模块支持;
- Varnish 采用内存型缓存,避免了频繁在内存、磁盘中交换文件,性能比 Squid 高;
- Varnish 由于是内存 cache,所以对小文件如 css、js、小图片的支持很棒,后端的持久化缓存可以采用的是 Squid 或 ATS;
- Squid 功能全而大,适合于各种静态的文件缓存,一般会在前端挂一个 HAProxy 或 Ngnix 做负载均衡跑多个实例;
- Nginx 采用第三方模块 ncache 做的缓冲,性能基本达到 Varnish,一般作为反向代理使用,可以实现简单的缓存。
4. 进程内缓存
进程内缓存是指应用内部的缓存,标准的分布式系统,一般有多级缓存构成。本地缓存是离应用最近的缓存,一般可以将数据缓存到硬盘或内存。
硬盘缓存- 将数据缓存到硬盘到,读取时从硬盘读取。原理是直接读取本机文件,减少了网络传输消耗,比通过网络读取数据库速度更快。可以应用在对速度要求不是很高,但需要大量缓存存储的场景。内存缓存- 直接将数据存储到本机内存中,通过程序直接维护缓存对象,是访问速度最快的方式。
常见的本地缓存实现方案:HashMap、Guava Cache、Caffeine、Ehcache。
4.1. ConcurrentHashMap
最简单的进程内缓存可以通过 JDK 自带的 HashMap 或 ConcurrentHashMap 实现。
适用场景:不需要淘汰的缓存数据。
缺点:无法进行缓存淘汰,内存会无限制的增长。
4.2. LRUHashMap
可以通过继承 LinkedHashMap 来实现一个简单的 LRUHashMap。重写 removeEldestEntry 方法,即可完成一个简单的最近最少使用算法。
- 缺点:
- 锁竞争严重,性能比较低。
- 不支持过期时间
- 不支持自动刷新
4.3. Guava Cache
解决了 LRUHashMap 中的几个缺点。
Guava Cache 采用了类似 ConcurrentHashMap 的思想,分段加锁,减少锁竞争。
Guava Cache 对于过期的 Entry 并没有马上过期(也就是并没有后台线程一直在扫),而是通过进行读写操作的时候进行过期处理,这样做的好处是避免后台线程扫描的时候进行全局加锁。
直接通过查询,判断其是否满足刷新条件,进行刷新。
4.4. Caffeine
Caffeine 实现了 W-TinyLFU(LFU+LRU 算法的变种),其命中率和读写吞吐量大大优于 Guava Cache。
其实现原理较复杂,可以参考你应该知道的缓存进化史。
4.5. 选择进程内缓存
| 比较项 | ConcurrentHashMap | LRUMap | Ehcache | Guava Cache | Caffeine |
|---|---|---|---|---|---|
| 读写性能 | 很好,分段锁 | 一般,全局加锁 | 好 | 好,需要做淘汰操作 | 很好 |
| 淘汰算法 | 无 | LRU,一般 | 支持多种淘汰算法,LRU,LFU,FIFO | LRU,一般 | W-TinyLFU, 很好 |
| 功能丰富程度 | 功能比较简单 | 功能比较单一 | 功能很丰富 | 功能很丰富,支持刷新和虚引用等 | 功能和 Guava Cache 类似 |
| 工具大小 | jdk 自带类,很小 | 基于 LinkedHashMap,较小 | 很大,最新版本 1.4MB | 是 Guava 工具类中的一个小部分,较小 | 一般,最新版本 644KB |
| 是否持久化 | 否 | 否 | 是 | 否 | 否 |
| 是否支持集群 | 否 | 否 | 是 | 否 | 否 |
ConcurrentHashMap- 比较适合缓存比较固定不变的元素,且缓存的数量较小的。虽然从上面表格中比起来有点逊色,但是其由于是 JDK 自带的类,在各种框架中依然有大量的使用,比如我们可以用来缓存我们反射的 Method,Field 等等;也可以缓存一些链接,防止其重复建立。在 Caffeine 中也是使用的ConcurrentHashMap来存储元素。LRUMap- 如果不想引入第三方包,又想使用淘汰算法淘汰数据,可以使用这个。Ehcache- 由于其 jar 包很大,较重量级。对于需要持久化和集群的一些功能的,可以选择 Ehcache。笔者没怎么使用过这个缓存,如果要选择的话,可以选择分布式缓存来替代 Ehcache。Guava Cache- Guava 这个 jar 包在很多 Java 应用程序中都有大量的引入,所以很多时候其实是直接用就好了,并且其本身是轻量级的而且功能较为丰富,在不了解 Caffeine 的情况下可以选择 Guava Cache。Caffeine- 其在命中率,读写性能上都比 Guava Cache 好很多,并且其 API 和 Guava cache 基本一致,甚至会多一点。在真实环境中使用 Caffeine,取得过不错的效果。
总结一下:如果不需要淘汰算法则选择 ConcurrentHashMap,如果需要淘汰算法和一些丰富的 API,推荐选择 Caffeine。
5. 分布式缓存
分布式缓存解决了进程内缓存最大的问题:如果应用是分布式系统,节点之间无法共享彼此的进程内缓存。
分布式缓存的应用场景:
- 缓存经过复杂计算得到的数据
- 缓存系统中频繁访问的热点数据,减轻数据库压力
不同分布式缓存的实现原理往往有比较大的差异。本文主要针对 Memcached 和 Redis 进行说明。
5.1. Memcache
Memcache 是一个高性能,分布式内存对象缓存系统,通过在内存里维护一个统一的巨大的 hash 表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。
简单的说就是:将数据缓存到内存中,然后从内存中读取,从而大大提高读取速度。
Memcache 特性
- 使用物理内存作为缓存区,可独立运行在服务器上。每个进程最大 2G,如果想缓存更多的数据,可以开辟更多的 Memcache 进程(不同端口)或者使用分布式 Memcache 进行缓存,将数据缓存到不同的物理机或者虚拟机上。
- 使用 key-value 的方式来存储数据。这是一种单索引的结构化数据组织形式,可使数据项查询时间复杂度为 O(1)。
- 协议简单,基于文本行的协议。直接通过 telnet 在 Memcached 服务器上可进行存取数据操作,简单,方便多种缓存参考此协议;
- 基于 libevent 高性能通信。Libevent 是一套利用 C 开发的程序库,它将 BSD 系统的 kqueue,Linux 系统的 epoll 等事件处理功能封装成一个接口,与传统的 select 相比,提高了性能。
- 分布式能力取决于 Memcache 客户端,服务器之间互不通信。各个 Memcached 服务器之间互不通信,各自独立存取数据,不共享任何信息。服务器并不具有分布式功能,分布式部署取决于 Memcached 客户端。
- 采用 LRU 缓存淘汰策略。在 Memcached 内存储数据项时,可以指定它在缓存的失效时间,默认为永久。当 Memcached 服务器用完分配的内时,失效的数据被首先替换,然后也是最近未使用的数据。在 LRU 中,Memcached 使用的是一种 Lazy Expiration 策略,自己不会监控存入的 key/vlue 对是否过期,而是在获取 key 值时查看记录的时间戳,检查 key/value 对空间是否过期,这样可减轻服务器的负载。
- 内置了一套高效的内存管理算法。这套内存管理效率很高,而且不会造成内存碎片,但是它最大的缺点就是会导致空间浪费。当内存满后,通过 LRU 算法自动删除不使用的缓存。
- 不支持持久化。Memcached 没有考虑数据的容灾问题,重启服务,所有数据会丢失。
Memcache 工作原理
(1)内存管理
Memcached 利用 slab allocation 机制来分配和管理内存,它按照预先规定的大小,将分配的内存分割成特定长度的内存块,再把尺寸相同的内存块分成组,数据在存放时,根据键值 大小去匹配 slab 大小,找就近的 slab 存放,所以存在空间浪费现象。
这套内存管理效率很高,而且不会造成内存碎片,但是它最大的缺点就是会导致空间浪费。
(2)缓存淘汰策略
Memcached 的缓存淘汰策略是 LRU + 到期失效策略。
当你在 Memcached 内存储数据项时,你有可能会指定它在缓存的失效时间,默认为永久。当 Memcached 服务器用完分配的内时,失效的数据被首先替换,然后是最近未使用的数据。
在 LRU 中,Memcached 使用的是一种 Lazy Expiration 策略:Memcached 不会监控存入的 key/vlue 对是否过期,而是在获取 key 值时查看记录的时间戳,检查 key/value 对空间是否过期,这样可减轻服务器的负载。
(3)分区
Memcached 服务器之间彼此不通信,它的分布式能力是依赖客户端来实现。
具体来说,就是在客户端实现一种算法,根据 key 来计算出数据应该向哪个服务器节点读/写。
而这种选取集群节点的算法常见的有三种:
- 哈希取余算法 - 使用公式:
hash(key)% N计算出 哈希值 来决定数据映射到哪一个节点。 - 一致性哈希算法 - 可以很好的解决 稳定性问题,可以将所有的 存储节点 排列在 首尾相接 的
Hash环上,每个key在计算Hash后会 顺时针 找到 临接 的 存储节点 存放。而当有节点 加入 或 退出 时,仅影响该节点在Hash环上 顺时针相邻 的 后续节点。 - 虚拟 Hash 槽算法 - 使用 分散度良好 的 哈希函数 把所有数据 映射 到一个 固定范围 的 整数集合 中,整数定义为 槽(
slot),这个范围一般 远远大于 节点数。槽 是集群内 数据管理 和 迁移 的 基本单位。采用 大范围槽 的主要目的是为了方便 数据拆分 和 集群扩展。每个节点会负责 一定数量的槽。
5.2. Redis
Redis 是一个开源(BSD 许可)的,基于内存的,多数据结构存储系统。可以用作数据库、缓存和消息中间件。
Redis 还可以使用客户端分片来扩展写性能。内置了 复制(replication),LUA 脚本(Lua scripting),LRU 驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis 哨兵(Sentinel)和自动分区(Cluster)提供高可用性(high availability)。
Redis 特性
支持多种数据类型 - string、hash、list、set、sorted set。
支持多种数据淘汰策略
- volatile-lru - 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
- volatile-ttl - 从已设置过期时间的数据集中挑选将要过期的数据淘汰
- volatile-random - 从已设置过期时间的数据集中任意选择数据淘汰
- allkeys-lru - 从所有数据集中挑选最近最少使用的数据淘汰
- allkeys-random - 从所有数据集中任意选择数据进行淘汰
- noeviction - 禁止驱逐数据
提供两种持久化方式 - RDB 和 AOF
通过 Redis cluster 提供集群模式。
Redis 原理
- 缓存淘汰
- Redis 有两种数据淘汰实现
- 消极方式 - 访问 Redis key 时,如果发现它已经失效,则删除它
- 积极方式 - 周期性从设置了失效时间的 key 中,根据淘汰策略,选择一部分失效的 key 进行删除。
- Redis 有两种数据淘汰实现
- 分区
- Redis Cluster 集群包含 16384 个虚拟 Hash 槽,它通过一个高效的算法来计算 key 属于哪个 Hash 槽。
- Redis Cluster 支持请求分发 - 节点在接到一个命令请求时,会先检测这个命令请求要处理的键所在的槽是否由自己负责,如果不是的话,节点将向客户端返回一个 MOVED 错误,MOVED 错误携带的信息可以指引客户端将请求重定向至正在负责相关槽的节点。
- 主从复制
- Redis 2.8 后支持异步复制。它有两种模式:
完整重同步(full resychronization)- 用于初次复制。执行步骤与SYNC命令基本一致。部分重同步(partial resychronization)- 用于断线后重复制。如果条件允许,主服务器可以将主从服务器连接断开期间执行的写命令发送给从服务器,从服务器只需接收并执行这些写命令,即可将主从服务器的数据库状态保持一致。
- 集群中每个节点都会定期向集群中的其他节点发送 PING 消息,以此来检测对方是否在线。
- 如果一个主节点被认为下线,则在其从节点中,根据 Raft 算法,选举出一个节点,升级为主节点。
- Redis 2.8 后支持异步复制。它有两种模式:
- 数据一致性
- Redis 不保证强一致性,因为这会使得集群性能大大降低。
- Redis 是通过异步复制来实现最终一致性。
5.3. 选择分布式缓存
不同的分布式缓存功能特性和实现原理方面有很大的差异,因此他们所适应的场景也有所不同。
这里选取三个比较出名的分布式缓存(MemCache,Redis,Tair)来作为比较:
| 比较项 | MemCache | Redis | Tair |
|---|---|---|---|
| 数据结构 | 只支持简单的 Key-Value 结构 | String,Hash, List, Set, Sorted Set | String,HashMap, List,Set |
| 持久化 | 不支持 | 支持 | 支持 |
| 容量大小 | 数据纯内存,数据存储不宜过多 | 数据全内存,资源成本考量不宜超过 100GB | 可以配置全内存或内存+磁盘引擎,数据容量可无限扩充 |
| 读写性能 | 很高 | 很高(RT0.5ms 左右) | String 类型比较高(RT1ms 左右),复杂类型比较慢(RT5ms 左右) |
| 过期策略 | 过期后,不删除缓存 | 有六种策略来处理过期数据 | 支持 |
MemCache- 这一块接触得比较少,不做过多的推荐。其吞吐量较大,但是支持的数据结构较少,并且不支持持久化。Redis- 支持丰富的数据结构,读写性能很高,但是数据全内存,必须要考虑资源成本,支持持久化。Tair- 支持丰富的数据结构,读写性能较高,部分类型比较慢,理论上容量可以无限扩充。
总结:如果服务对延迟比较敏感,Map/Set 数据也比较多的话,比较适合 Redis。如果服务需要放入缓存量的数据很大,对延迟又不是特别敏感的话,那就可以选择 Tair。
6. 多级缓存
6.1. 使用进程内缓存
如果应用服务不是分布式系统,那么进程内缓存当然是缓存的首选方案。
对于进程内缓存,其本来受限于内存的大小的限制,以及进程缓存更新后其他缓存无法得知,所以一般来说进程缓存适用于:
- 数据量不是很大且更新频率较低的数据。
- 如果更新频繁的数据,也想使用进程内缓存,那么可以将其过期时间设置为较短的时间,或者设置较短的自动刷新时间。
这种方案存在以下问题:
- 如果应用服务是分布式系统,应用节点之间无法共享缓存,存在数据不一致问题。
- 由于进程内缓存受限于内存大小的限制,所以缓存不能无限扩展。
6.2. 使用分布式缓存
如果应用服务是分布式系统,那么最简单的缓存方案就是直接使用分布式缓存。
其应用场景如图所示:
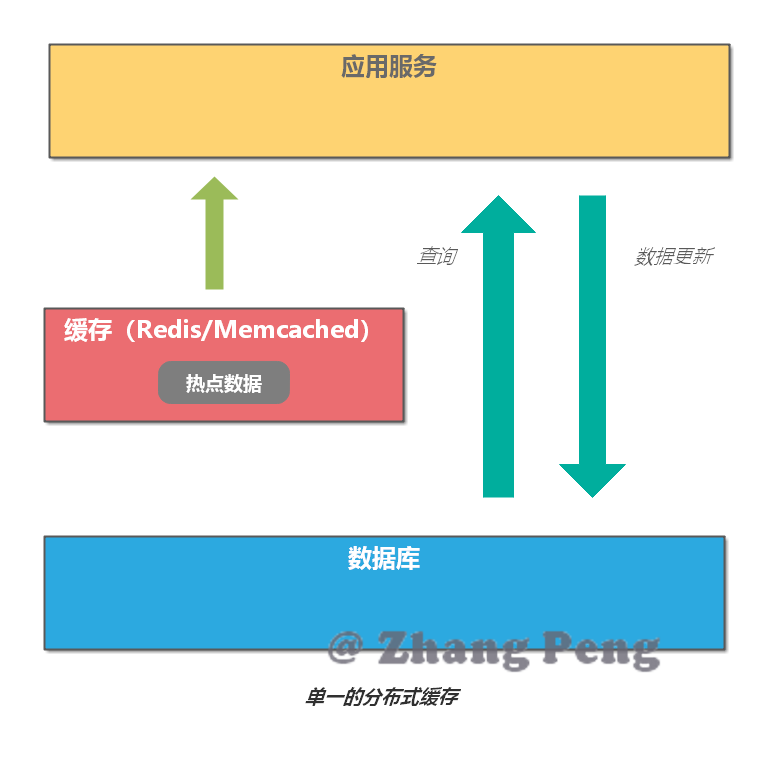
这种方案存在以下问题:
- 缓存服务如果挂了,这时应用只能访问数据库,容易造成缓存雪崩。
- 访问分布式缓存服务会有一定的 I/O 以及序列化反序列化的开销,虽然性能很高,但是其终究没有在内存中查询快。
6.3. 使用多级缓存
单纯使用进程内缓存和分布式缓存都存在各自的不足。如果需要更高的性能以及更好的可用性,我们可以将缓存设计为多级结构。将最热的数据使用进程内缓存存储在内存中,进一步提升访问速度。
这个设计思路在计算机系统中也存在,比如 CPU 使用 L1、L2、L3 多级缓存,用来减少对内存的直接访问,从而加快访问速度。
一般来说,多级缓存架构使用二级缓存已可以满足大部分业务需求,过多的分级会增加系统的复杂度以及维护的成本。因此,多级缓存不是分级越多越好,需要根据实际情况进行权衡。
一个典型的二级缓存架构,可以使用进程内缓存(如: Caffeine/Google Guava/Ehcache/HashMap)作为一级缓存;使用分布式缓存(如:Redis/Memcached)作为二级缓存。
多级缓存查询
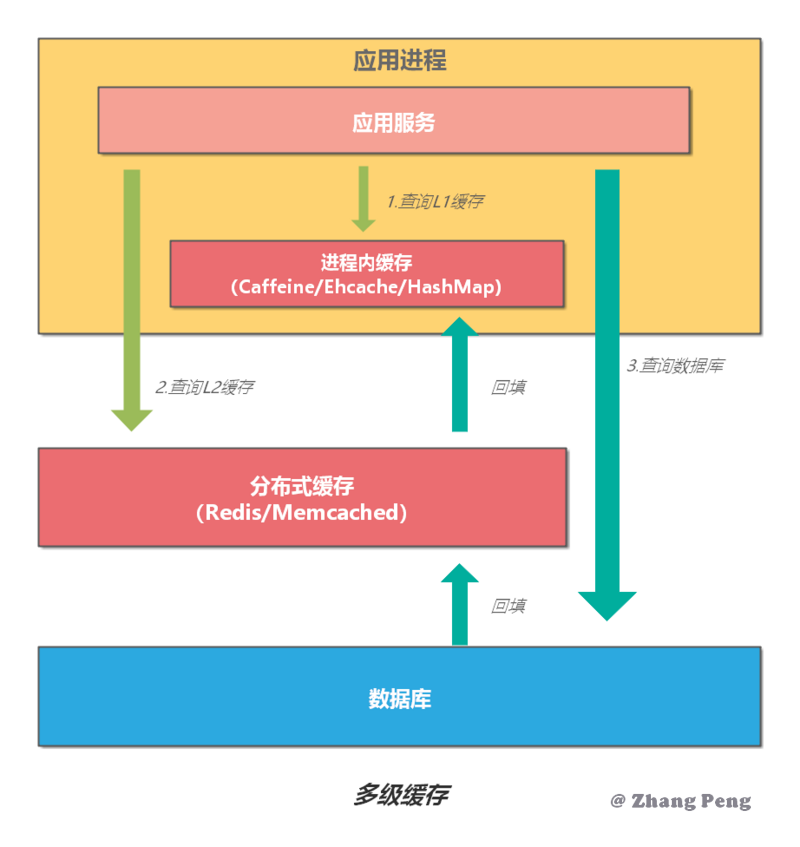
- 首先,查询 L1 缓存,如果缓存命中,直接返回结果;如果没有命中,执行下一步。
- 接下来,查询 L2 缓存,如果缓存命中,直接返回结果并回填 L1 缓存;如果没有命中,执行下一步。
- 最后,查询数据库,返回结果并依次回填 L2 缓存、L1 缓存。
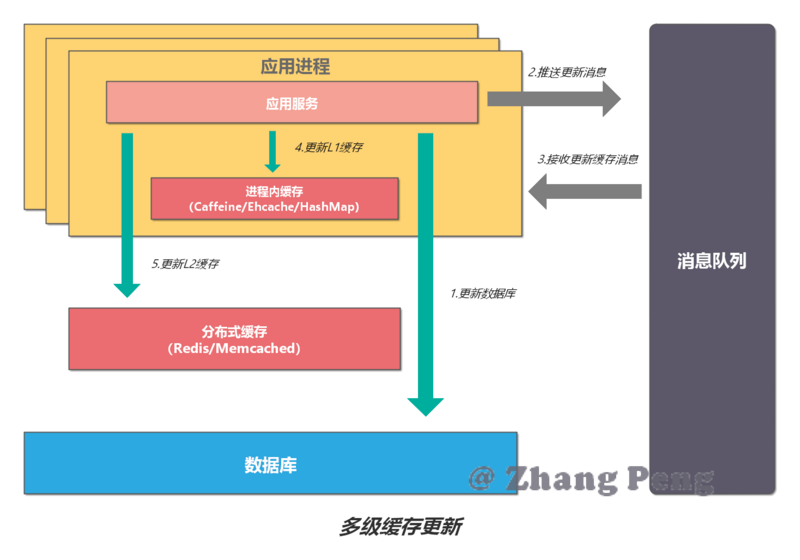
多级缓存更新
对于 L1 缓存,如果有数据更新,只能删除并更新所在机器上的缓存,其他机器只能通过超时机制来刷新缓存。超时设定可以有两种策略:
- 设置成写入后多少时间后过期
- 设置成写入后多少时间刷新
对于 L1 缓存,如果有数据更新,其他机器立马可见。但是,也必须要设置超时时间,其时间应该比 L1 缓存的有效时间长。
为了解决进程内缓存不一致的问题,设计可以进一步优化:
7. 缓存问题
7.1. 缓存雪崩
缓存雪崩是指缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩。
解决方案:
- 增加缓存系统可用性。通过监控关注缓存的健康程度,根据业务量适当的扩容缓存。
- 采用多级缓存。不同级别缓存设置的超时时间不同,即使某个级别缓存都过期,也有其他级别缓存兜底。
- 缓存的过期时间可以取个随机值。比如以前是设置 10 分钟的超时时间,那每个 Key 都可以随机 8-13 分钟过期,尽量让不同 Key 的过期时间不同。
- 对数据库进行过载保护或应用层限流。
7.2. 缓存穿透
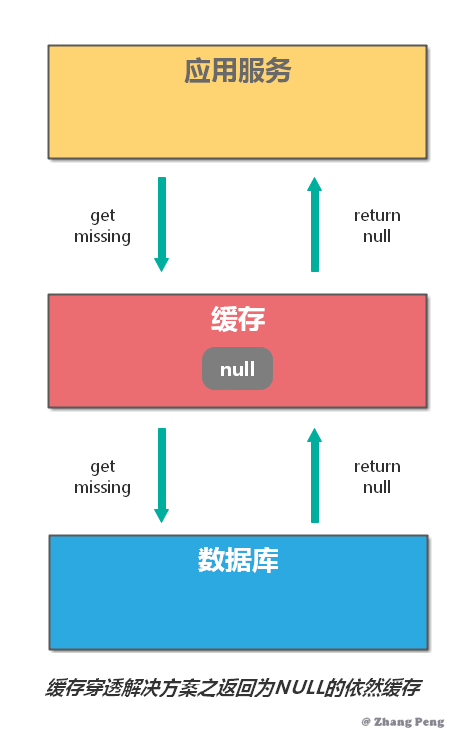
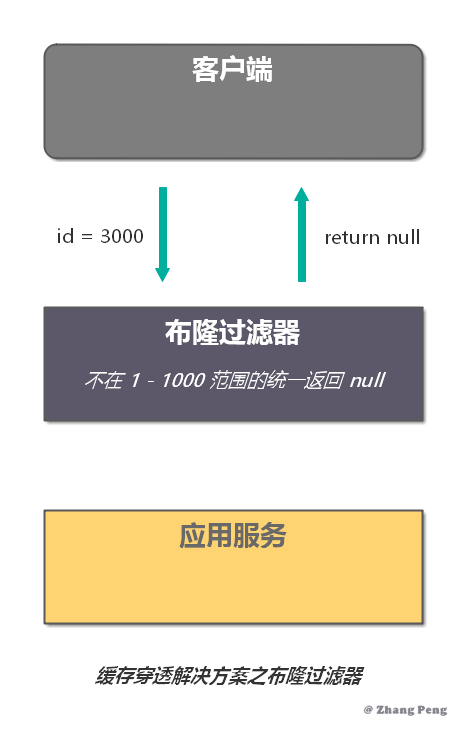
缓存穿透是指:查询的数据在数据库中不存在,那么缓存中自然也不存在。所以,应用在缓存中查不到,则会去查询数据库。当这样的请求多了后,数据库的压力就会增大。
解决缓存穿透,一般有两种方法:
- 对于返回为 NULL 的依然缓存,对于抛出异常的返回不进行缓存。
- 过滤不可能存在的数据
7.3. 缓存击穿
对于某些 key 设置了过期时间,但是其是热点数据,如果某个 key 失效,可能大量的请求打过来,缓存未命中,然后去数据库访问,此时数据库访问量会急剧增加。
为了避免这个问题,我们可以采取下面的两个手段:
- 分布式锁 - 锁住热点数据的 key,避免大量线程同时访问同一个 key。
- 异步加载 - 可以对部分数据采取到期自动刷新的策略,而不是到期自动淘汰。淘汰其实也是为了数据的时效性,所以采用自动刷新也可以。
7.4. 缓存更新
一般来说缓存的更新有两种情况:
- 先删除缓存,再更新数据库。
- 先更新数据库,再删除缓存。
为什么是删除缓存,而不是更新缓存呢?
你可以想想当有多个并发的请求更新数据,你并不能保证更新数据库的顺序和更新缓存的顺序一致,那就会出现数据库中和缓存中数据不一致的情况。所以一般来说考虑删除缓存。
- 先删除缓存,再更新数据库
对于一个更新操作简单来说,就是先去各级缓存进行删除,然后更新数据库。
这个操作有一个比较大的问题,在对缓存删除完之后,有一个读请求,这个时候由于缓存被删除所以直接会读库,读操作的数据是老的并且会被加载进入缓存当中,后续读请求全部访问的老数据。
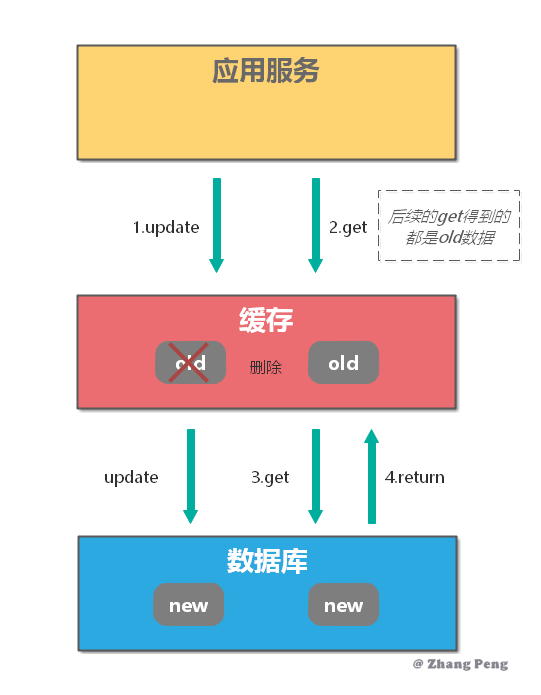
先删除缓存也有一个好处是,如果对数据库操作失败了,那么由于先删除的缓存,最多只是造成 Cache Miss。
- 先更新数据库,再删除缓存
注:更推荐使用这种策略
如果我们使用更新数据库,再删除缓存就能避免上面的问题。
但是同样的引入了新的问题:假设执行更新操作时,又接收到查询请求,此时就会返回缓存中的老数据。更麻烦的是,如果数据库更新操作执行失败,则缓存中可能永远是脏数据。
- 应该选择哪种更新测录
通过上面的内容,我们知道,两种更新策略都存在并发问题。
但是建议选择先更新数据库,再删除缓存,因为其并发问题出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
如果需要数据库和缓存保证强一致性,则可以通过 2PC 或 Paxos 协议来实现。但是 2PC 太慢,而 Paxos 太复杂,所以如果不是非常重要的数据,不建议使用强一致性方案。
7.5. 缓存预热
缓存预热是指系统启动后,将常用的数据直接缓存。这样就可以避免用户请求的时候,先查询数据库,然后再更新缓存的问题。
解决方案:
- 直接写个缓存刷新页面,上线时手工操作下。
- 数据量不大,可以在项目启动的时候自动进行加载。
- 定时刷新缓存。
7.6. 缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
参考资料
网络通信之 VPN
网络通信之 VPN
📦 本文已归档到:「blog」
简介
虚拟专用网络(VPN)的功能是:在公用网络上建立专用网络,进行加密通讯。在企业网络中有广泛应用。VPN 网关通过对数据包的加密和数据包目标地址的转换实现远程访问。VPN 可通过服务器、硬件、软件等多种方式实现。
VPN 属于远程访问技术,简单地说就是利用公用网络架设专用网络。例如某公司员工出差到外地,他想访问企业内网的服务器资源,这种访问就属于远程访问。
在传统的企业网络配置中,要进行远程访问,传统的方法是租用 DDN(数字数据网)专线或帧中继,这样的通讯方案必然导致高昂的网络通讯和维护费用。对于移动用户(移动办公人员)与远端个人用户而言,一般会通过拨号线路(Internet)进入企业的局域网,但这样必然带来安全上的隐患。
让外地员工访问到内网资源,利用 VPN 的解决方法就是在内网中架设一台 VPN 服务器。外地员工在当地连上互联网后,通过互联网连接 VPN 服务器,然后通过 VPN 服务器进入企业内网。为了保证数据安全,VPN 服务器和客户机之间的通讯数据都进行了加密处理。有了数据加密,就可以认为数据是在一条专用的数据链路上进行安全传输,就如同专门架设了一个专用网络一样,但实际上 VPN 使用的是互联网上的公用链路,因此 VPN 称为虚拟专用网络,其实质上就是利用加密技术在公网上封装出一个数据通讯隧道。有了 VPN 技术,用户无论是在外地出差还是在家中办公,只要能上互联网就能利用 VPN 访问内网资源,这就是 VPN 在企业中应用得如此广泛的原因。
VPN 的作用
隐藏 IP 和位置

VPN 可以隐藏使用者的 IP 地址和位置。
使用 VPN 的最常见原因之一是屏蔽您的真实 IP 地址。
您的 IP 地址是由 ISP 分配的唯一数字地址。 您在线上所做的所有事情都链接到您的 IP 地址,因此可以用来将您与在线活动进行匹配。 大多数网站记录其访问者的 IP 地址。
广告商还可以使用您的 IP 地址,根据您的身份和浏览历史为您提供有针对性的广告。
连接到 VPN 服务器时,您将使用该 VPN 服务器的 IP 地址。 您访问的任何网站都会看到 VPN 服务器的 IP 地址,而不是您自己的。
您将能够绕过 IP 地址阻止并浏览网站,而不会将您的活动作为一个个人追溯到您。
通信加密

使用 VPN 时,可以对信息进行加密,使得密码,电子邮件,照片,银行数据和其他敏感信息不会被拦截。
如果在公共场所使用公共 WiFi 连接网络时,敏感数据有被盗的风险。黑客可以利用开放和未加密的网络来窃取重要数据,例如您的密码,电子邮件,照片,银行数据和其他敏感信息。
VPN 可以加密信息,使黑客更难以拦截和窃取数据。
翻墙

轻松解除对 Facebook 和 Twitter,Skype,YouTube 和 Gmail 等网站和服务的阻止。 即使您被告知您所在的国家/地区不可用它,或者您所在的学校或办公室网络限制访问,也可以获取所需的东西。
某些服务(例如 Netflix 或 BBC iPlayer)会根据您访问的国家/地区限制访问内容。使用 VPN 可以绕过这些地理限制并解锁“隐藏”内容的唯一可靠方法。
避免被监听

使用 VPN 可以向政府、ISP、黑客隐藏通信信息。
您的 Internet 服务提供商(ISP)可以看到您访问的所有网站,并且几乎可以肯定会记录该信息。
在某些国家/地区,ISP 需要长时间收集和存储用户数据,并且政府能够访问,存储和搜索该信息。
在美国,英国,澳大利亚和欧洲大部分地区就是这种情况,仅举几例。
由于 VPN 会加密从设备到 VPN 服务器的互联网流量,因此您的 ISP 或任何其他第三方将无法监视您的在线活动。
要了解有关监视技术和全球大规模监视问题的更多信息,请访问 EFF 和 Privacy International。 您还可以在此处找到全球监视披露的更新列表。
工作原理
VPN 会在您的设备和私人服务器之间建立私人和加密的互联网连接。 这意味着您的数据无法被 ISP 或任何其他第三方读取或理解。 然后,私有服务器将您的流量发送到您要访问的网站或服务上。
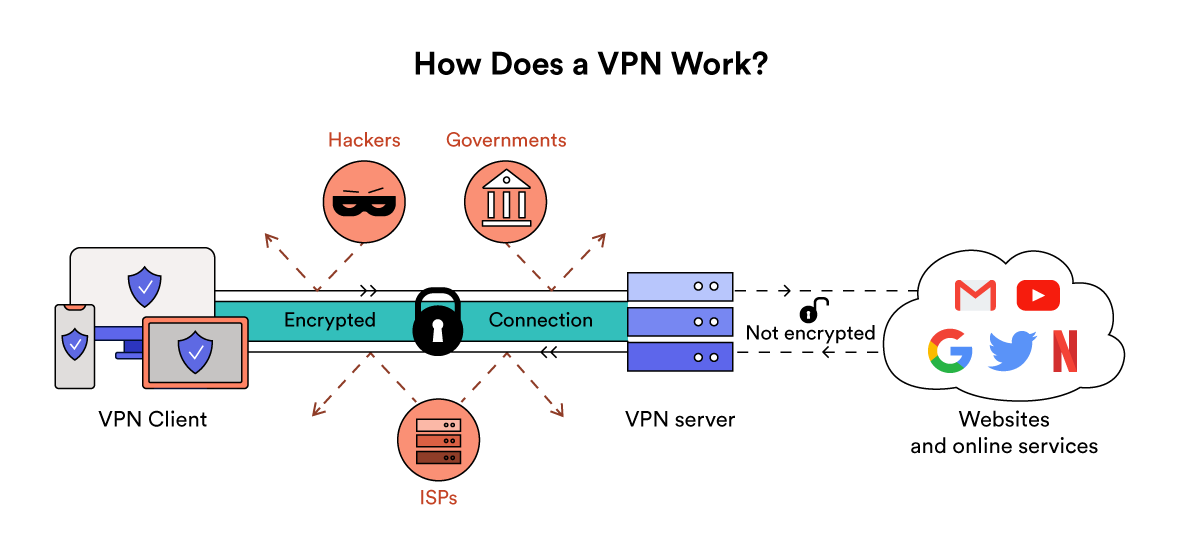
VPN 的基本处理过程如下:
- 要保护主机发送明文信息到其他 VPN 设备。
- VPN 设备根据网络管理员设置的规则,确定是对数据进行加密还是直接传输。
- 对需要加密的数据,VPN 设备将其整个数据包(包括要传输的数据、源 IP 地址和目的 lP 地址)进行加密并附上数据签名,加上新的数据报头(包括目的地 VPN 设备需要的安全信息和一些初始化参数)重新封装。
- 将封装后的数据包通过隧道在公共网络上传输。
- 数据包到达目的 VPN 设备后,将其解封,核对数字签名无误后,对数据包解密。
VPN 协议
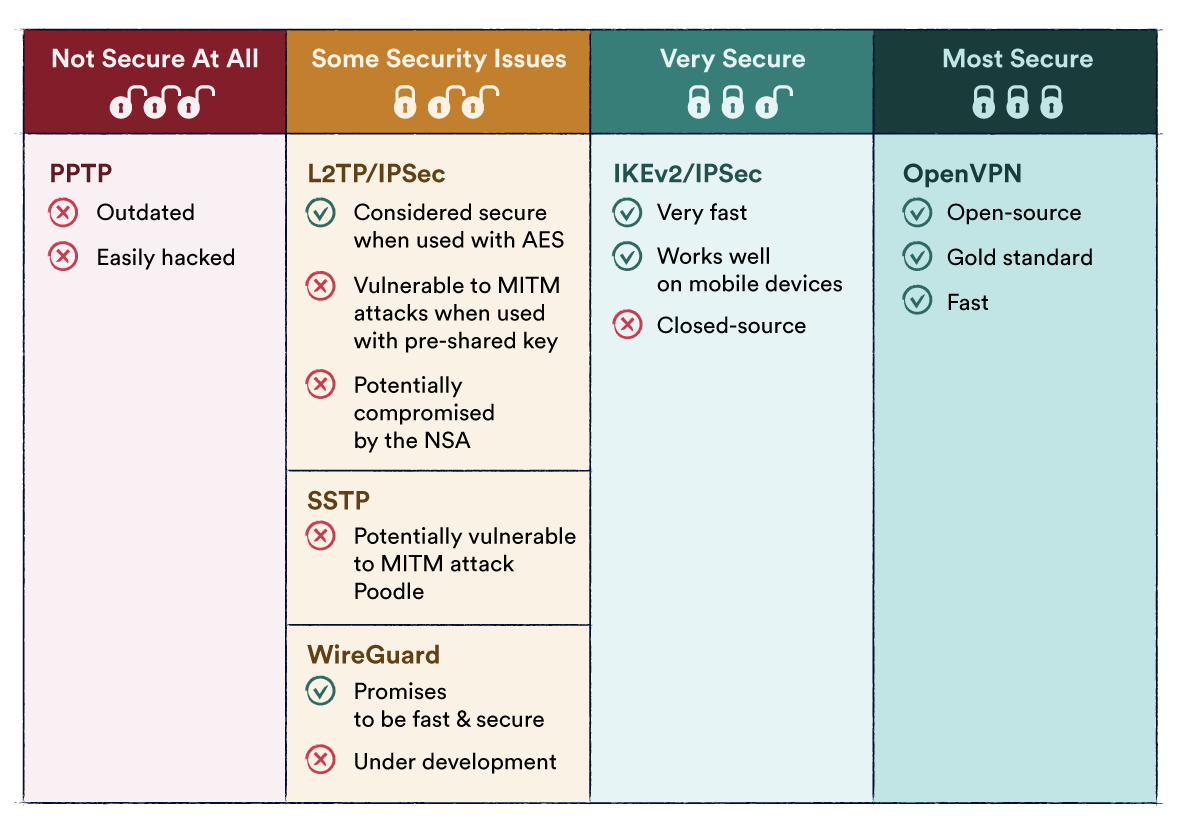
OpenVPN
IKEv2 / IPSec
SSTP
PPTP
Wireguard
VPN 服务
你可以选择付费 VPN 或自行搭建 VPN。
VPN 服务商:
开源 VPN:
参考资料
深入剖析共识性算法 Paxos
深入剖析共识性算法 Paxos
📦 本文已归档到:「blog」
Paxos 是一种基于消息传递且具有容错性的共识性(consensus)算法。
Paxos 算法解决的问题正是分布式一致性问题。在一个节点数为 N 的分布式集群中,只要半数以上的节点(N/2 + 1)还正常工作,整个系统仍可以正常工作。

一、Paxos 背景
Paxos 是 Leslie Lamport 于 1990 年提出的一种基于消息传递且具有高度容错特性的共识(consensus)算法。
为描述 Paxos 算法,Lamport 虚拟了一个叫做 Paxos 的希腊城邦,这个岛按照议会民主制的政治模式制订法律,但是没有人愿意将自己的全部时间和精力放在这种事情上。所以无论是议员,议长或者传递纸条的服务员都不能承诺别人需要时一定会出现,也无法承诺批准决议或者传递消息的时间。
二、Basic Paxos 算法
角色
Paxos 将分布式系统中的节点分为以下角色:
- 提议者(Proposer):发出提案(Proposal)。Proposal 信息包括提案编号 (Proposal ID) 和提议的值 (Value)。
- 决策者(Acceptor):参与决策,回应 Proposer 的提案。收到 Proposal 后可以接受提案,若 Proposal 获得多数 Acceptor 的接受,则称该 Proposal 被批准。
- 学习者(Learner):不参与决策,从 Proposers/Acceptors 学习最新达成一致的提案(Value)。
在复制状态机中,每个副本都同时具有 Proposer、Acceptor、Learner 三种角色。

算法
Paxos 算法通过一个决议分为两个阶段(Learn 阶段之前决议已经形成):
- 第一阶段:Prepare 阶段。Proposer 向 Acceptors 发出 Prepare 请求,Acceptors 针对收到的 Prepare 请求进行 Promise 承诺。
- 第二阶段:Accept 阶段。Proposer 收到多数 Acceptors 承诺的 Promise 后,向 Acceptors 发出 Propose 请求,Acceptors 针对收到的 Propose 请求进行 Accept 处理。
- 第三阶段:Learn 阶段。Proposer 在收到多数 Acceptors 的 Accept 之后,标志着本次 Accept 成功,决议形成,将形成的决议发送给所有 Learners。
Paxos 算法流程中的每条消息描述如下:
Prepare: Proposer 生成全局唯一且递增的 Proposal ID (可使用时间戳加 Server ID),向所有 Acceptors 发送 Prepare 请求,这里无需携带提案内容,只携带 Proposal ID 即可。
Promise: Acceptors 收到 Prepare 请求后,做出“两个承诺,一个应答”。
两个承诺:
- 不再接受 Proposal ID 小于等于当前请求的 Prepare 请求。
- 不再接受 Proposal ID 小于当前请求的 Propose 请求。
一个应答:
- 不违背以前作出的承诺下,回复已经 Accept 过的提案中 Proposal ID 最大的那个提案的 Value 和 Proposal ID,没有则返回空值。
Propose: Proposer 收到多数 Acceptors 的 Promise 应答后,从应答中选择 Proposal ID 最大的提案的 Value,作为本次要发起的提案。如果所有应答的提案 Value 均为空值,则可以自己随意决定提案 Value。然后携带当前 Proposal ID,向所有 Acceptors 发送 Propose 请求。
Accept: Acceptor 收到 Propose 请求后,在不违背自己之前作出的承诺下,接受并持久化当前 Proposal ID 和提案 Value。
Learn: Proposer 收到多数 Acceptors 的 Accept 后,决议形成,将形成的决议发送给所有 Learners。
实例
Paxos 算法实例 1
下面举几个例子,实例 1 如下图:
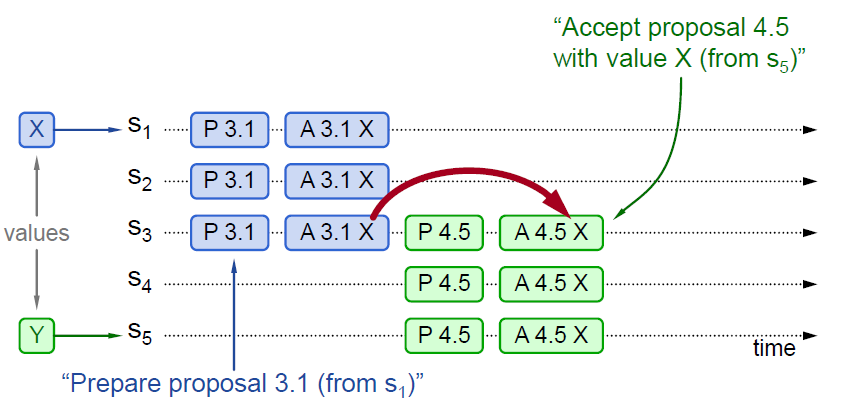
图中 P 代表 Prepare 阶段,A 代表 Accept 阶段。3.1 代表 Proposal ID 为 3.1,其中 3 为时间戳,1 为 Server ID。X 和 Y 代表提议 Value。
实例 1 中 P 3.1 达成多数派,其 Value(X)被 Accept,然后 P 4.5 学习到 Value(X),并 Accept。
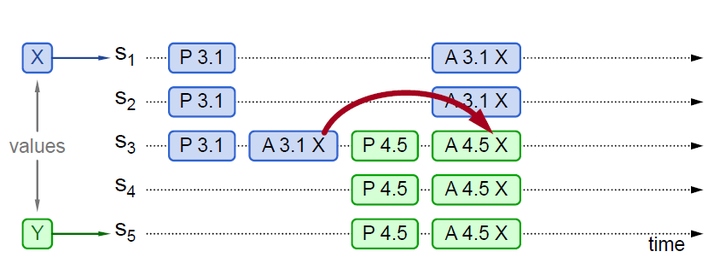 Paxos 算法实例 2
Paxos 算法实例 2
实例 2 中 P 3.1 没有被多数派 Accept(只有 S3 Accept),但是被 P 4.5 学习到,P 4.5 将自己的 Value 由 Y 替换为 X,Accept(X)。
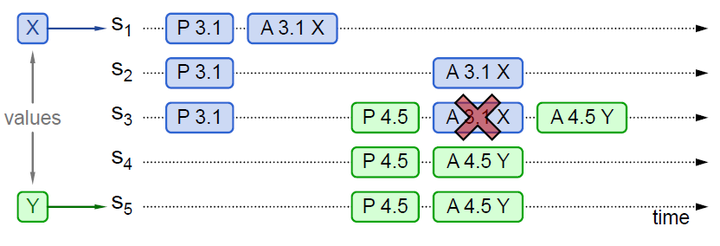 Paxos 算法实例 3
Paxos 算法实例 3
实例 3 中 P 3.1 没有被多数派 Accept(只有 S1 Accept),同时也没有被 P 4.5 学习到。由于 P 4.5 Propose 的所有应答,均未返回 Value,则 P 4.5 可以 Accept 自己的 Value (Y)。后续 P 3.1 的 Accept (X) 会失败,已经 Accept 的 S1,会被覆盖。
Paxos 算法可能形成活锁而永远不会结束,如下图实例所示:
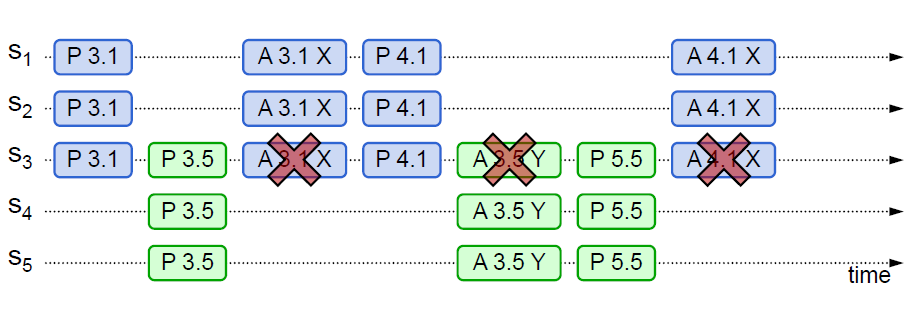 Paxos 算法形成活锁
Paxos 算法形成活锁
回顾两个承诺之一,Acceptor 不再应答 Proposal ID 小于等于当前请求的 Prepare 请求。意味着需要应答 Proposal ID 大于当前请求的 Prepare 请求。
两个 Proposers 交替 Prepare 成功,而 Accept 失败,形成活锁(Livelock)。
三、Multi Paxos 算法
Basic Paxos 的问题
Basic Paxos 有以下问题,导致它不能应用于实际:
- Basic Paxos 算法只能对一个值形成决议。
- Basic Paxos 算法会消耗大量网络带宽。Basic Paxos 中,决议的形成至少需要两次网络通信,在高并发情况下可能需要更多的网络通信,极端情况下甚至可能形成活锁。如果想连续确定多个值,Basic Paxos 搞不定了。
Multi Paxos 的改进
Multi Paxos 正是为解决以上问题而提出。Multi Paxos 基于 Basic Paxos 做了两点改进:
- 针对每一个要确定的值,运行一次 Paxos 算法实例(Instance),形成决议。每一个 Paxos 实例使用唯一的 Instance ID 标识。
- 在所有 Proposer 中选举一个 Leader,由 Leader 唯一地提交 Proposal 给 Acceptor 进行表决。这样没有 Proposer 竞争,解决了活锁问题。在系统中仅有一个 Leader 进行 Value 提交的情况下,Prepare 阶段就可以跳过,从而将两阶段变为一阶段,提高效率。
Multi Paxos 首先需要选举 Leader,Leader 的确定也是一次决议的形成,所以可执行一次 Basic Paxos 实例来选举出一个 Leader。选出 Leader 之后只能由 Leader 提交 Proposal,在 Leader 宕机之后服务临时不可用,需要重新选举 Leader 继续服务。在系统中仅有一个 Leader 进行 Proposal 提交的情况下,Prepare 阶段可以跳过。
Multi Paxos 通过改变 Prepare 阶段的作用范围至后面 Leader 提交的所有实例,从而使得 Leader 的连续提交只需要执行一次 Prepare 阶段,后续只需要执行 Accept 阶段,将两阶段变为一阶段,提高了效率。为了区分连续提交的多个实例,每个实例使用一个 Instance ID 标识,Instance ID 由 Leader 本地递增生成即可。
Multi Paxos 允许有多个自认为是 Leader 的节点并发提交 Proposal 而不影响其安全性,这样的场景即退化为 Basic Paxos。
Chubby 和 Boxwood 均使用 Multi Paxos。ZooKeeper 使用的 Zab 也是 Multi Paxos 的变形。
参考资料
分布式基础原理
分布式基础原理

📦 本文已归档到:「blog」
大型网站几乎都是分布式系统。分布式系统的最大难点,在于各节点的状态如何同步。CAP 定理是这方面的基本定理,也是理解分布式系统的起点。
一、拜占庭将军问题
拜占庭将军问题是由莱斯利·兰波特在其同名论文中提出的分布式对等网络通信容错问题。
在分布式计算中,不同的节点通过通讯交换信息达成共识而按照同一套协作策略行动。但有时候,系统中的节点可能出错而发送错误的信息,用于传递信息的通讯网络也可能导致信息损坏,使得网络中不同的成员关于全体协作的策略得出不同结论,从而破坏系统一致性。拜占庭将军问题被认为是容错性问题中最难的问题类型之一。
问题描述:
一群拜占庭将军各领一支军队共同围困一座城市。
为了简化问题,军队的行动策略只有两种:进攻(Attack,后面简称 A)或撤退(Retreat,后面简称 R)。如果这些军队不是统一进攻或撤退,就可能会造成灾难性后果,因此将军们必须通过投票来达成一致策略:同进或同退。
因为将军们分别在城市的不同方位,所以他们只能通过信使互相联系。在投票过程中,每位将军都将自己的投票信息(A 或 R)通知其他所有将军,这样一来每位将军根据自己的投票和其他所有将军送来的信息就可以分析出共同的投票结果而决定行动策略。
这个抽象模型的问题在于:将军中可能存在叛徒,他们不仅会发出误导性投票,还可能选择性地发送投票信息。
由于将军之间需要通过信使通讯,叛变将军可能通过伪造信件来以其他将军的身份发送假投票。而即使在保证所有将军忠诚的情况下,也不能排除信使被敌人截杀,甚至被敌人间谍替换等情况。因此很难通过保证人员可靠性及通讯可靠性来解决问题。
假使那些忠诚(或是没有出错)的将军仍然能通过多数决定来决定他们的战略,便称达到了拜占庭容错。在此,票都会有一个默认值,若消息(票)没有被收到,则使用此默认值来投票。
上述的故事映射到分布式系统里,将军便成了机器节点,而信差就是通信系统。
二、CAP
CAP 定理是加州大学计算机科学家埃里克·布鲁尔提出来的猜想,后来被证明成为分布式计算领域公认的定理。
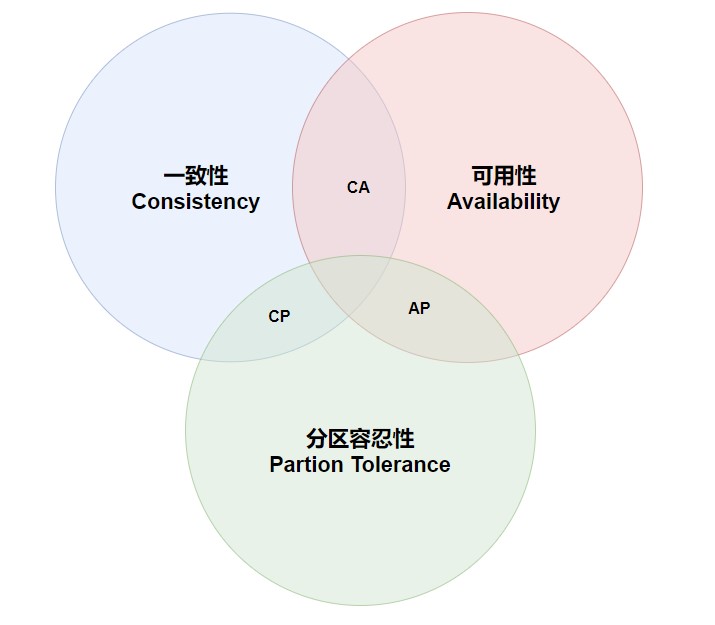
CAP 定理又称为 CAP 原则,指的是:在一个分布式系统中, 一致性(C:Consistency)、可用性(A:Availability) 和 分区容忍性(P:Partition Tolerance),最多只能同时满足其中两项。
分区容错性
分区容错性(Partition Tolerance)指 分布式系统在遇到任何网络分区故障的时候,仍然需要能对外提供一致性和可用性的服务,除非是整个网络环境都发生了故障。
大多数分布式系统都分布在多个子网络,每个子网络就叫做一个区(Partition)。分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。

上图中,G1 和 G2 是两台跨区的服务器。G1 向 G2 发送一条消息,G2 可能无法收到。系统设计的时候,必须考虑到这种情况。
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,剩下的 C 和 A 无法同时做到。
一致性
一致性(Consistency)指的是多个数据副本是否能保持一致的特性。
在一致性的条件下,分布式系统在执行写操作成功后,如果所有用户都能够读取到最新的值,该系统就被认为具有强一致性。
举例来说,某条记录是 v0,用户向 G1 发起一个写操作,将其改为 v1。

接下来,用户的读操作就会得到 v1。这就叫一致性。

问题是,用户有可能向 G2 发起读操作,由于 G2 的值没有发生变化,因此返回的是 v0。G1 和 G2 读操作的结果不一致,这就不满足一致性了。

为了让 G2 也能变为 v1,就要在 G1 写操作的时候,让 G1 向 G2 发送一条消息,要求 G2 也改成 v1。

这样的话,用户向 G2 发起读操作,也能得到 v1。

可用性
可用性指分布式系统在面对各种异常时可以提供正常服务的能力,可以用系统可用时间占总时间的比值来衡量,4 个 9 的可用性表示系统 99.99% 的时间是可用的。
在可用性条件下,系统提供的服务一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
权衡
在分布式系统中,分区容忍性必不可少,因为需要总是假设网络是不可靠的。因此,CAP 理论实际在是要在可用性和一致性之间做权衡。
可用性和一致性往往是冲突的,很难都使它们同时满足。在多个节点之间进行数据同步时,
- 为了保证一致性(CP),就需要让所有节点下线成为不可用的状态,等待同步完成;
- 为了保证可用性(AP),在同步过程中允许读取所有节点的数据,但是数据可能不一致。
三、BASE
BASE 是 基本可用(Basically Available)、软状态(Soft State) 和 最终一致性(Eventually Consistent) 三个短语的缩写。
BASE 理论是对 CAP 中一致性和可用性权衡的结果,它的理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。

基本可用
基本可用(Basically Available)指分布式系统在出现故障的时候,保证核心可用,允许损失部分可用性。
例如,电商在做促销时,为了保证购物系统的稳定性,部分消费者可能会被引导到一个降级的页面。
软状态
软状态(Soft State)指允许系统中的数据存在中间状态,并认为该中间状态不会影响系统整体可用性,即允许系统不同节点的数据副本之间进行同步的过程存在延时。
最终一致性
最终一致性(Eventually Consistent)强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能达到一致的状态。
ACID 要求强一致性,通常运用在传统的数据库系统上。而 BASE 要求最终一致性,通过牺牲强一致性来达到可用性,通常运用在大型分布式系统中。
在实际的分布式场景中,不同业务单元和组件对一致性的要求是不同的,因此 ACID 和 BASE 往往会结合在一起使用。